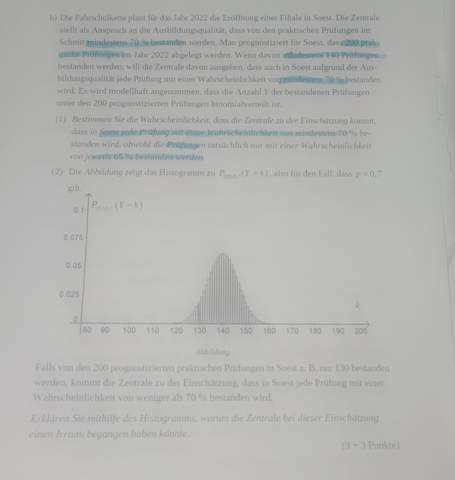
Weg zum KI-Ingenieur?
Hallo liebe Comunity,
ich gehe im Moment noch in die Schule, könnte mir aber vorstellen zukünftig etwas im Bereich des maschinellen Lernens zu machen. Deswegen würde ich gerne jetzt schon einen Grundstein dafür legen. Ich habe mich aber gefragt, wie man da am besten einsteigen könnte. Mein Plan war es jetzt, erst mal meine mathematischen Kentnisse aufzufrischen und den Schulstoff der letzen Jahre Mathe zu wiederholen. Darauf aufbauend wollte ich dann in die höhere Mathematik einsteigen und mich mit linearer Algebra, Stochastik & Statistik befassen.
Danach würde ich dann beginnen mir das Programmieren beizubringen. In Python kenne ich mich schon ein bisschen aus, aber ich würde mein Können als definitiv ausbaufähig beschreiben.
Als letzen Schritt würde ich mich dann mit KI-spezifischen Themen auseinandersetzen. Da hab ich mir jedoch noch nichts genaueres überlegt. Wahrscheinlich beständer der Teil dann darin, die Struktur von neuronalen Netzen tiefer zu durchblicken, mit KI-Frameworks zu experimentieren und verschiedene Trainingsmethoden auszuprobieren (Supervised learning, Reinforcment learning, etc.)
Aber ich bin halt echt alles andere als Experte in diesem Bereich (das will ich ja erst noch werden in Zukunft). Deswegen bitte ich darum, mögliche Fehler in meiner Nachricht zu entschuldigen.
Jetzt zu meiner Frage an alle, die sich mit KI auskennen, selber in diesem Bereich tätig sind oder sich auf dem Weg dahin befinden.
Was haltet ihr von meinem Plan. Würdet ihr anders vorgehen? habe ich irgendetwas wichtiges vergessen? Würdet ihr das Erlernen dieser Fähigkeiten anders strukturieren?
Über eine simple Bewertung und ein paar Ratschläge würde ich mich sehr freuen.
Viele Grüße und noch einen schönen Sonntag :)