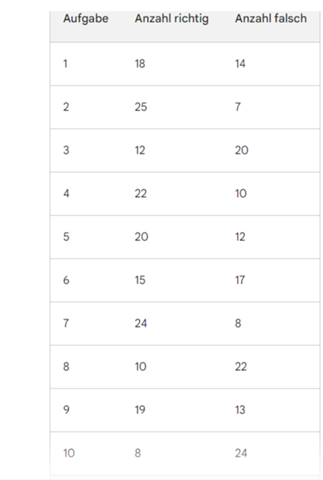
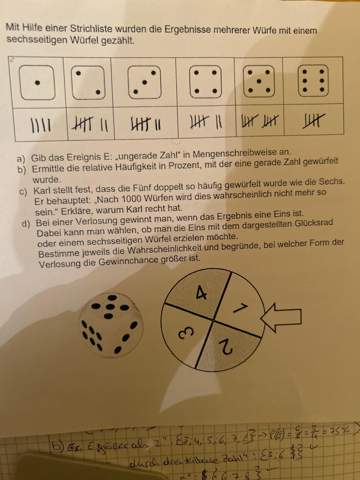
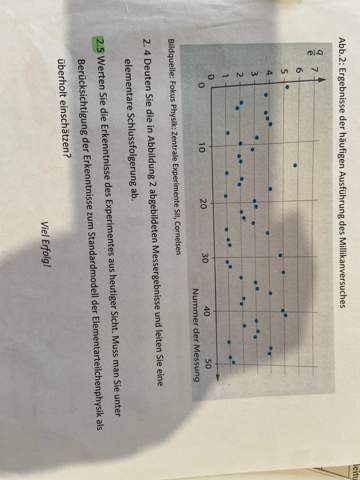
Hallo.
Ich habe zwei Freundinnen. Wir treffen uns gemeinsam leider nur alle 3-4 Monate. Wenn wir uns sehen ist es aber absolut super , erfrischend wir führen vertraute Gespräche und fühlen uns alle super wohl. Alle sagen danach immer wie toll es war.
Warum treffen wir uns so selten?
1. eine lebt in einer andern Stadt und ist daher nicht direkt vor Ort sondern muss erst anreisen oder das Treffen mit Terminen in der Stadt verbinden
2 Wir haben alle viel um die Ohren und viele Verpflichtungen aber ganz unterschiedliche Alltage und Jobsituationen
Naja, eigentlich haben wir den September für ein nächste Treffen ins Auge gefasst. Nun sind wir heute draufgekommen, dass es eher mitte Oktober wird, da eine fast den ganzen September im Urlaub ist und in der ersten Oktoberwoche noch berufliche Fortbildungen hat und meint sie hat dann Abends keinen Kopf mehr. Also wir das Treffen irgendwann ab dem 8.10 sein. Das wollen wir demnächst fixieren je nachdem wann die dritte da kann.
Heißt dass, dass ihr diese Freundschaft nicht wichtig ist. Sie meinte sie freut sich schon so aber hat früher schwer Zeit. Ist das schlimm? Kommt es auf die zwei, drei Wochen mehr oder weniger Abstand zwischen den treffen drauf an oder nicht?
Das letzte gemeinsame Treffen war im Juni, dazwischen waren auch viele Termine bei allen, sei es beruflich, Urlaub und Schulferien und ein Umzug von einer aus der Runde der sie auch sehr in Anspruch genommen hat und viele Prüfungen von diversen Weiterbildungen.
bin so traurig, dass wir uns so selten sehen und frage mich ob das keine wertvolle Freundschaft ist.