SQL Summe von der aktuellen Woche bekommen?
Hey, ich versuche aus SQL die Summe einer Spalte im Zeitraum von einer Woche zu bekommen (Also vom 01-01-2022 - 07-01-2022). Dabei habe ich folgenden Code versucht, der jedoch nicht das gewünschte Ergebnis erbringt (leider kommt gar nichts dabei raus)
Habt ihr eine Ahnung wo der Fehler liegt und wie man mein Vorhaben richtig umsetzen kann?
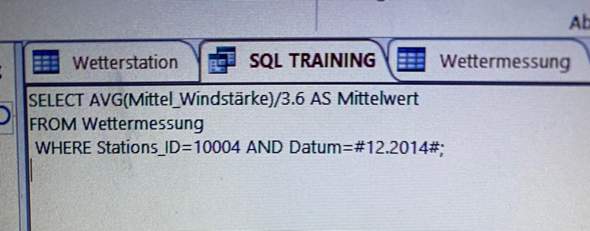
"SELECT SUM(" + dbHelper.NOTES + ") FROM " + dbHelper.TABLE_NAME + " WHERE " + dbHelper.DATE + " BETWEEN 01-01-2022 AND 07-01-2022";
In meiner SQL-Datenbank wurde das Datum TEXT abgespeichert, ist das richtig? Oder sollte ein Datum in der Datenbank normalerweise einen anderen Datentypen haben?
LG
Computer,
SQL,
programmieren,
Java,
Datenbank,
Informatik