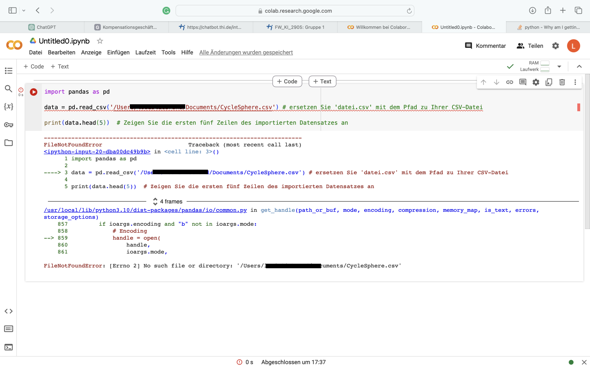
Ich habe ein Python Script erstellt, damit später bei Nachrichten bestimmte befehle ausgeführt werden. Beim ersten Script(Openhab_Mqtt.py) habe ich beim Testen 3 Terminals aufgemacht und beim 2.(Openhab_Mqttv2.py) auch genau gleiche Sorgehensweise.
Im 1. Terminal habe ich das Python Script gestartet mit:
python Openhab_Mqttv2.py
Output:
Script 1: Connected to MQTT broker
Script 2: Connected to MQTT broker
Connected to MQTT broker
Im 2. Terminal habe ich die Nachricht ausgegeben bei Nachrichten mit:
mosquitto_sub -t "main/messager" -v -u xxx -P xxx
Output(Nach T3):
Script 1: main/messager test
Script 2: main/messager test
Und im 3. Terminal habe ich eine Nachricht gesendet mit:
mosquitto_pub -t "main/messager" -m "test" -u xxx-P xxx
Output:
Script 1: Payload: test und BLA...
Script 2:
Ich kann einfach nicht den Fehler finden, warum es bei Openhab_Mqtt.py funktioniert und bei Openhab_Mqttv2.py nicht funktioniert.
Openhab_Mqtt.py DATA:
import paho.mqtt.client as mqtt
import os
import time
import bme280_temp
import smbus2
import bme280
import threading
def on_subscribe(client, userdata, mid, granted_qos):
print("Subscribed to topic : " + str(mid) +" with QoS" + str(granted_qos))
def on_connect(client, userdata, flags, rc):
print("Connected to MQTT broker")
def on_message(client, userdata, msg):
print(msg.topic+" "+str(msg.qos)+" "+str(msg.payload))
print("Payload: " + msg.payload.decode())
if msg.payload.decode() == "send_signal":
print("Calling script to send signal...")
IR_Signal()
if msg.payload.decode() == "temp_bme280_start":
print("Calling script to for temperature start...")
userdata["counter"] += 1
print(str(userdata["counter"]))
client.publish("frame/monitor", "START", qos=0, retain=True)
Temp_sensor()
if msg.payload.decode() == "temp_bme280_stop":
print("Calling script to for temperature stop...")
userdata["counter"] -= 1
print(str(userdata["counter"]))
client.publish("frame/monitor", "STOP", qos=0, retain=True)
if msg.payload.decode() == "test":
print("BLA...")
print(str(["counter"]))
os.system("vcgencmd measure_temp")
else:
pass
#Bme280_basic Temperature
address = 0x76
bus = smbus2.SMBus(1)
calibration_params = bme280.load_calibration_params(bus, address)
def Temp_sensor():
data = bme280.sample(bus, address, calibration_params)
temperature_celsius = data.temperature
print("Temperature: {:.2f} °C".format(temperature_celsius))
time.sleep(2)
def IR_Signal():
os.system("irsend SEND_ONCE pioneer_vsx-301 KEY_POWER")
print ("Signal Send!")
client = mqtt.Client()
client.on_message = on_message
client.on_connect = on_connect
client.user_data_set({"counter": 0})
client.username_pw_set( "xx" , "xx" )
client.connect( "192.x.x.x", 1883, 60)
client.subscribe( "main/messager" , qos=0)
client.loop_forever()
Openhab_Mqttv2.py
import paho.mqtt.client as mqtt
import time
import smbus2
import bme280
import threading
# Getting information
def on_subscribe(client, userdata, mid, granted_qos):
print("Subscribed to topic : " + str(mid) +" with QoS" + str(granted_qos))
def on_connect(client, userdata, flags, rc):
print("Connected to MQTT broker")
# Damit loops nicht am anfang durchstarten
TempLoop_running = False
# Checking for messages to execute code
def on_message(client, userdata, msg):
print(msg.topic+" "+str(msg.qos)+" "+str(msg.payload))
print("Payload: " + msg.payload.decode())
if msg.payload.decode() == "Temp_Start":
start_TempLoop()
if msg.payload.decode() == "Temp_Stop":
stop_TempLoop()
if msg.payload.decode() == "test":
print("TESTING...")
client.publish("main/messager", "START", qos=0, retain=True)
else:
pass
# Execute things here ->
# Getting Temperature
address = 0x76
bus = smbus2.SMBus(1)
# Load calibration parameters
calibration_params = bme280.load_calibration_params(bus, address)
def Temperature_loop():
global TempLoop_running
while TempLoop_running:
data = bme280.sample(bus, address, calibration_params)
#Extract temperature, pressure, and humidity
temperature_celsius = data.temperature
#Print the readings
print("Temperature: {:.2f} °C".format(temperature_celsius))
# Nachricht an das entsprechende Topic senden
client.publish("Temp/Loop", "Temperature: {:.2f} °C".format(temperature_celsius))
# Wartezeit, um die Ausgabe zu verlangsamen
time.sleep(2)
# Funktion zum Starten der Temperatur Schleife
def start_TempLoop():
global TempLoop_running
TempLoop_running = True
threading.Thread(target=Temperature_loop).start()
# Funktion zum Stoppen der Temperatur Schleife
def stop_TempLoop():
global TempLoop_running
TempLoop_running = False
# Set general data
client = mqtt.Client()
client.on_message = on_message
client.on_connect = on_connect
client.connect( "192.x.x.x", 1883, 60)
client.username_pw_set( "xx", "xx" )
client.subscribe( "main/messager", qos=0)
# Loop forever
client.loop_forever()