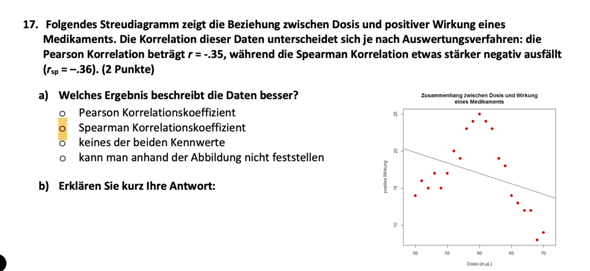
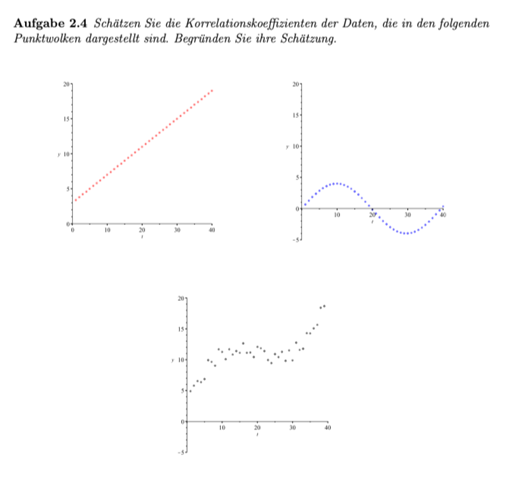
Die Frage zielt darauf ab, zu untersuchen, ob es einen Zusammenhang zwischen der Inflation, also dem allgemeinen Anstieg des Preisniveaus, und einer Zunahme der Kriminalitätsrate gibt.
**Hintergrund der Frage:**
Inflation führt dazu, dass die Kaufkraft des Geldes abnimmt – Menschen können sich mit dem gleichen Einkommen weniger leisten als zuvor. In wirtschaftlich schwierigen Zeiten könnten einige Personen aufgrund von finanziellen Schwierigkeiten oder sozialer Ungleichheit eher geneigt sein, kriminelle Handlungen zu begehen. Daher wird die Frage gestellt, ob eine steigende Inflation zu einem Anstieg der Kriminalität führen kann.
**Mögliche Überlegungen:**
- **Wirtschaftlicher Druck:** Wenn die Lebenshaltungskosten steigen, könnten Menschen, die sich in einer prekären finanziellen Lage befinden, auf illegale Aktivitäten zurückgreifen, um ihren Lebensunterhalt zu sichern. Dies könnte besonders in Zeiten hoher Inflation der Fall sein, wenn Löhne und Gehälter nicht mit den steigenden Preisen Schritt halten.
- **Soziale Spannungen:** Inflation kann auch zu größerer sozialer Ungleichheit führen, da Menschen mit niedrigem Einkommen stärker betroffen sind als wohlhabendere Bevölkerungsschichten. Diese Ungleichheit könnte soziale Spannungen verstärken, was zu einem Anstieg bestimmter Arten von Kriminalität führen könnte.
- **Historische und statistische Daten:** Um einen Zusammenhang zwischen Inflation und Kriminalität nachzuweisen, müsste man historische Daten analysieren. Dabei könnte man untersuchen, ob in Zeiten hoher Inflation auch die Kriminalitätsrate gestiegen ist und ob es andere Faktoren gibt, die diesen Anstieg erklären könnten.
**Zusammenfassend:** Die Frage untersucht, ob es eine Verbindung zwischen Inflation und einer Zunahme der Kriminalität gibt. Sie zielt darauf ab zu klären, ob und wie wirtschaftliche Faktoren wie Inflation das Verhalten von Menschen beeinflussen und ob dies zu einer Zunahme krimineller Aktivitäten führt.