C#: Wie kann ich aus dem HTTP Response Code zum Beispiel nur den Textinhalt herausfiltern?
Hallo,
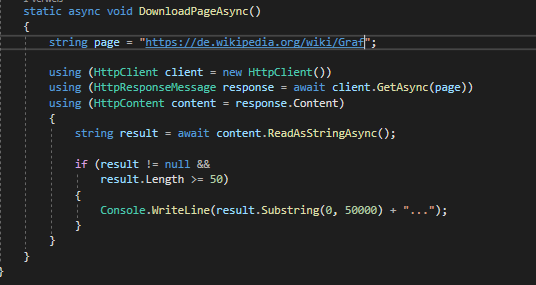
ich habe mit HttpResponseMessage den Inhalt eines Wikipedia-Eintrags geladen.
Allerdings gibt es mir den gesamten Code zurück. Wie kann ich nun daraus zum Beispiel nur den Textinhalt filtern? Muss ich es mit Split nun so schneiden und alles herausfiltern oder gibt es da noch eine andere Möglichkeit?
4 Antworten
Dies oder reguläre Ausdrücke wären eine Möglichkeit. Einfacher macht es dir allerdings das Html Agility Pack. Mit diesem lässt sich der String als HTML Document Tree auswerten, mittels XPath-Ausdrücken kannst du nach entsprechenden Knoten suchen.
HTML verarbeitet man üblicherweise mit einem HTML-Parser. Dein Programm hält dann so lange, bis Wiki irgendetwas an der Website verändert.
Ansonsten ist es eine eher dürftige Notlösung, die Inhalte aus einer Website rauszuparsen, wenn es auch eine bessere Möglichkeit in Form einer kleinen API gibt:
https://en.wikipedia.org/wiki/Special:Export
Da genügt in diesem Fall ein normaler XML-Parser, den jede bessere Programmiersprache mitliefern sollte.
Du musst den Code mit Split() zerlegen und den teil den du brauchst herausfinden
Bedeutet für jede "< html> </html" ect eine split anweisung ?
Bitte bei C# - Fragen nicht Java, Javascript und/oder C++ markieren !