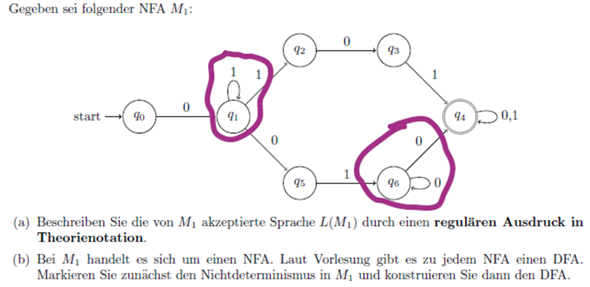
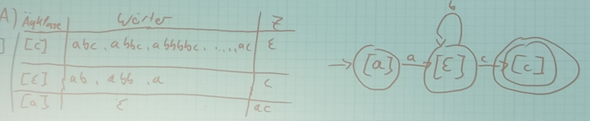
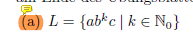Ich habe gerade gelernt, dass man jedes Entscheidungsproblem L1 über Σ in P auf jedes andere Problem L2 über Σ aus P reduzieren kann. Mit hat es hier "die Kette rausgehauen":
Eine Reduktion ist ja eine berechenbare Abbildung
jetzt könnte ich festlegen Σ = Natürliche Zahlen von 1 bis 1 Million
L1 = {w ∈ Σ | w ist prim)
L2 = {w ∈ Σ | w ist gerade)
und definieren:
f(w) = 6 wenn w prim
f(w) = 7 wenn w nicht prim
Dies erfüllt genau die obige Definition einer Reduktion.
Nur welchen Sinn macht es, hier von einer "Reduktion" zu sprechen, denn ich habe ja den Primtest auf eine Zahl nicht auf den Test auf Geradheit einer Zahl zurückgeführt.
Ich hätte intuitiv etwas als Reduktion bezeichnet, wenn ich durch die Entscheidung L2 auch L1 entscheiden kann. Hier liegt aber aus meiner Laiensicht ein "fauler Zauber" vor, denn in der Abbildungsvorschrift f ist eigentlich schon enthalten, dass ich dafür schon die Entscheidung auf Prim durchführen, also L1 lösen muss. Es "hört sich aber so an", als könnte man nun einen Primtest (der ja, obwohl in P liegend, relativ komplex ist) auf etwas "reduzieren", wo man nur auf Geradheit prüft (was ja von der Komplexität nicht vergleichbar ist). Jedenfalls ist das nicht im Sinne der Erfindung eines "funktionierenden" Algorithmus für L1, den ich zu lösen vermag, indem ich L2 löse.
Ich hoffe, ich habe mich in meiner Notation verständlich ausgedrückt und man weiß, was ich meine...(bin kein Informatiker, daher bitte Milde walten lassen ;-)
Habe ich eine falsche Vorstellung von einer Reduktion oder ist das einfach so?