Python 3: Ich habe Fragen zur Implementation des Huffman-Code. Könnt ihr mir helfen?
Hallo Leute,
ich hoffe, dass ich hiermit nicht den Shitstorm of Doom heraufbeschwöre, aber ich komme seit fünf Tagen partout nicht weiter.
1) (2 Punkte) Gegeben sei folgende Nachricht: ”Mississippi River in Ontario isn’t Mississippi River in Mississippi!”
Zeichne den zugehörigen Huffman-Baum und stelle die Codetabelle auf, wie sie es in der Vorlesung gelernt haben. Geben Sie alle erforderlichen Werte an! Wie lautet die oben angegebene Nachricht in ihrer codierten Form?
2) (2 Punkte) Schreibe ein Python 3.7.x Programm, welches die in der Aufgabe 11.1 aufgestellte Codetabelle beinhaltet. Das Programm soll Befehle encode und decode verstehen und die darauffolgende Eingabe codieren oder decodieren können. Falsche Eingaben sind mit einer Warnung in der Konsole zu quittieren. Geben jeweils 5 Testfälle für Codierung und Decodierung an. Zusätzlich gebe an, wie Deine Implementierung die Nachricht
3) (4 Punkte) Schreibe ein in Python 3.7.x Programm, welches eine Eingabe (Nachricht) über die Konsole entgegennimmt, sie analysiert und basierend darauf eine Codetabelle aufbaut.
- Gebe diese Codetabelle in der Konsole aus.
- Gebe die codierte Eingabe in der Konsole aus.
- Implementiere eine Funktion zur Decodierung und gebe die decodierte Nachricht zur Verifikation in der Konsole aus.
Setze die Befehle newbase und showtable um. Ermögliche damit eine neue Eingabe und lasse für diese eine neue Codetabelle berechnen und gegebenenfalls ausgeben. Setze weiterhin Befehle encode und decode um, wie Du es in der Aufgabe 11.2 gemacht hast.
Hinweise:
Zur Lösung dieser Aufgabe dürfen built-in Sortiermethoden verwendet werden. Denke daran, dass nicht alle Datentypen geordnet sind. Dennoch können hier auch solche Datentypen sehr hilfreich sein.
Nicht lauffähige Programme werden nicht bewertet, dabei gilt als Maßstab NUR die Ausführbarkeit in der Konsole!
Aufgabe 1 hab ich noch lösen können,

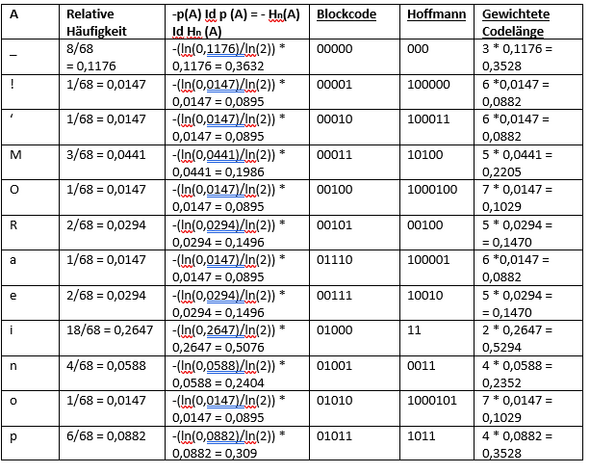

Ich weiß, im Netz gibt es gefühlt 3000 Huffman Code-Tutorials, aber die sind alle auf fortgeschrittenen Niveau und erklären auch nicht, wie ich diese Code-Tabelle implementieren soll. Zur Erklärung:
- Spalte 1: Die relative Häufigkeit, wie oft ein Zeichen allgemein im String vorkommt.
- Spalte 2: Der Logarithmus dualis:
- Spalte 3: Blockcode der Reihe nach aufgeschrieben
- Spalte 4: Der Huffman Code (auf den 0 und 1 in der Grafik basierend)
- Spalte 5: Gewichtete Codelänge (Anzahl der Bits im Huffman-Code * Relative Häufigkeit)
Wie kann ich das in Python berechnen lassen und zusätzlich noch in so einer Tabellenform ausgeben? Dazu müsste man doch alle Werte von diesem Baum manuell eintragen, oder nicht?
Kann ich bei Aufgabe 2) nicht einfach die Variablen neu definieren, z.B. "M == 000" oder ist das geschummelt?
3 Antworten
Aufgabe 3 beinhaltet Aufgabe 2. Daher hier meine Lösung für Aufgabe 3 auf die Schnelle:
import math
from texttable import Texttable
class Tree:
def __init__(self, chars = None, freq = None):
self.left = None
self.right = None
self.chars = chars
self.freq = freq
sum1 = 0
sum2 = 0
table = None
text = None
def newbase():
global sum1, sum2, table, text
text = input("Eingabe: ")
table = {}
for c in text:
if (not c in table):
table[c] = [1 / len(text)]
else:
table[c][0] += 1 / len(text)
trees = []
for r in table:
trees.append(Tree(r, table[r][0]))
while (len(trees) > 1):
trees.sort(key=lambda x: x.freq)
newTree = Tree(trees[0].chars + trees[1].chars, \
trees[0].freq + trees[1].freq)
newTree.left = trees[0]
newTree.right = trees[1]
trees.append(newTree)
trees.pop(0)
trees.pop(0)
tree = trees[0]
for i, c in enumerate(table):
l = table[c]
s1 = -((math.log(l[0])) / math.log(2)) * l[0]
sum1 += s1
l.append(s1)
form = "{0:0" + str(math.ceil(math.log(len(table), 2))) + "b}"
l.append(form.format(i))
huffman = ""
t = tree
while (t != None):
if (t.left != None and c in t.left.chars):
huffman += "0"
t = t.left
elif (t.right != None and c in t.right.chars):
huffman += "1"
t = t.right
else:
t = None
l.append(huffman)
s2 = len(huffman) * l[0]
sum2 += s2
l.append(s2)
return table
def showtable():
t = Texttable()
t.add_row(["A", "Relative Häufigkeit", "-p(A) ld p(A)", "Blockcode", \
"Huffmann", "Gewichtete Codelänge"])
for k, v in table.items():
t.add_row([k] + v)
t.add_row(["Summe", 1, str(sum1) + " bit", \
str(math.ceil(math.log(len(table), 2))) + " bit", "", str(sum2) + " bit"])
print(t.draw())
def encode():
encoded = ""
for c in text:
encoded += table[c][3]
return encoded
def decode(encoded):
decoded = ""
i = 0
while i < len(encoded):
j = i + 1
c = None
while (c == None):
s = encoded[i:j]
for k, v in table.items():
if (v[3] == s):
c = k
j += 1
decoded += c
i = j-1
return decoded
table = newbase()
showtable()
encoded = encode()
print (encoded)
decoded = decode(encoded)
print(decoded)
Live-Test: https://repl.it/@tavkomann/Huffman
Im Endeffekt habe ich mich für ein Dictionary entschieden, welches jedem Buchstaben eine Liste mit den restlichen Tabellenspalten zuordnet. Außerdem habe ich einen ganz grundlegenden Baum implementiert.
Schau dir das einfach mal an und versuche es nachzuvollziehen. Das könnte dich für deine eigene Lösung inspirieren. Solltest du konkrete Fragen zu meinem Code haben, frage einfach nach ;-)
Vielen Dank nochmals. Ja, Module dürfen benutzt werden. Wusste nur gar nicht, dass es so Features wie pip3 gibt. Sehr nützlich!
Zu Aufgabe 2:
Dein erstes Ziel sollte die Implementation eines Binärbaums sein. Diesen kannst du dann mit deinen Werten füllen und für die folgende De-/Kodierung verwenden.
Ein Binärbaum ist ziemlich simpel. Du brauchst im Grunde nur ein Objekt Knoten, welches zum einen einen Wert, und zum anderen zwei Kindknoten beinhalten kann (ggbfs. sind natürlich noch weitere Attribute möglich, die bspw. die Häufigkeit angeben). Für die Kindknoten würde ich eine Liste verwenden, welche im Index 0 den linken Kindknoten und im Index 1 den rechten Kindknoten trägt.
Eine Instanz der Baumstruktur baust du dir zu Beginn der Anwendung dann einmal komplett zusammen. Ein sehr simples Beispiel für einen Baum mit den Werten 1, 2 und 3:
left = Node(2, None, None)
right = Node(3, None, None)
root = Node(1, left, right)
Für eine Kodierung müsstest du folgend nur über die Zeichen der Nachricht zu laufen und je Zeichen den Weg im Baum zu ermitteln. Das bedeutet, dass eine Suche im Baum notwendig ist: Welcher Knoten trägt das aktuelle Zeichen? Im einfachsten Fall setzt du Rekursion ein und läufst somit die Knoten so lange ab, bis es einen Fund gab. Eine erste Optimierung in dem Sinne wäre das vorherige Ermitteln aller notwendigen Buchstaben - heißt, du iterierst über die Zeichen der Nachricht und streichst erst einmal alle doppelten Zeichen heraus, damit nach einem e bspw. nicht mehrmals der Binärcode herausgefunden werden muss.
Die Dekodierung bedeutet ebenso eine Art Traversierung über den Baum. Geh durch jedes Zeichen der kodierten Nachricht, wandle es in eine Zahl um und nutze es als Brotkrumen, um dir im Baum einen Weg zu bahnen. Wenn du auf einen Knoten triffst, der keine Kindelemente mehr besitzt (bzw. ein Zeichen hält), weißt du, dass du beim nachfolgenden kodierten Zeichen wieder beim Wurzelknoten starten kannst.
Wenn etwas mit der Nachricht nicht passt (das un-/kodierte Zeichen kann im Baum nicht gefunden werden), weißt du, dass etwas nicht stimmt und kannst die Operation abbrechen.
Zu Aufgabe 3:
Hier gilt es, zunächst einmal den Eingabestring zu analysieren:
- Welche Länge hat er?
- Welche Buchstaben kommen wie oft vor? Dafür könnte man sich bspw. für jeden Buchstaben einen Eintrag in einem Dictionary anlegen und in diesem die Anzahl zählen:
# only some pseudo code:
for character in message:
if dict.hasKey(character):
dict[character] = dict[character] + 1
else:
dict.put(character, 1)
So lässt sich für jedes Zeichen eine relative Häufigkeit berechnen (Anzahl/Wortlänge) und ebenso deine zweite Spalte.
Danach müsstest du dir, anhand der berechneten Häufigkeit, einen konkreten Baum generieren lassen. Ich verlinke dir dazu einmal einen Thread, in dem ein rekursiver Algorithmus für so etwas aufgezeigt wird:
Wenn du jedem Knoten mehrere Attribute zuordnest (Häufigkeit, Huffman-Code, etc.), reicht es womöglich später, nur einmal über den erzeugten Baum zu rennen, um alle Informationen zu erhalten, die für die Tabelle auf der Konsole ausgegeben werden müssen.
Kann ich bei Aufgabe 2) nicht einfach die Variablen neu definieren, z.B. "M == 000" oder ist das geschummelt?
Das verstehe ich nicht. Nimm einfach den Baum als Datenmodell, nichts anderes. Wenn dieser richtig aufgebaut wurde, sind die Knoten schon nach Häufigkeit ihrer Werte entsprechend angeordnet.
Das Konzept hinter der Huffman-Codierung ist es, eine Nachricht zu komprimieren. Dies kann über das Datenformat erreicht werden und indem häufige Buchstaben mit einem kürzeren Weg im Baum gekennzeichnet werden.
Bei (2) soll, wie es sich liest, die Tabelle statisch verwendet werden. D.h. Du sollst auch keine neue Tabelle für andere Eingaben verwenden. Von daher ist da der Baum noch unnötig. (Und ja, das heißt auch, daß NAchrichten it anderen Buchstaben nicht funktionieren - vermutlich deswegen die Testfälle ;-).
Letztlich sollen die Aufgaben wohl den Beantwortenden am Nasenring durch die Manege führen *g*.
Fertigen Code gibt es nicht (Ja, sorry, buuuuh, böse), aber ich kann Dir ein paar Denkanstöße geben:
Die statische Tabelle kannst du entweder als Tupel von Tupel, liste in listen, oder liste von Dictionaries oder Dictonary von listen hinterlegen. Je nachdem wie schmerzfrei Du bist, ist eine der Optionen die angehmste.
codetab={'-': [ 8/86, -math.log(8/86),2)*8/86, 0000, ...],'!':[.....],....}
So kannst du dann bei anderen Nachrichten die Buchstaben mit codetab['!'][...] als Lookup einfach kodieren. (Du könntest natürlich auch dict idn dict machen und hast dann eben jedesmal die Feldnamen, aber das alles händishc zu tippen ist ja auch irgendwie ekelig :-).
Du kannst auch die Befüllung automatisieren, indem Du nur die wichtigen Werte angibst und den Rest berechnest.
Wenn Du die Codetabelle für eine beliebige Eingabe aufbauen sollst, dann kannst Du ein Dictionary als Buchstabenhistogramm nutzen ...
Oder Du definierst eine Klasse als Baumknoten und baust einen Baum auf, die Tabelle wäre dann nur noch die lineare (ggf. sortierte) Ausgabe des Baumes.
Erstmal vielen vielen dank für die Implementierung. Das rettet mich wirklich sehr (und vorallem die Klausurzulassung^^). Das ist für Linux geschrieben, richtig?
Der Python-Intetrpeter meldet bei mir " ModuleNotFoundError: No module named 'texttable'". Muss ich jetzt nochmal ne py.Datei mit Texttable anlegen. Oder klappt der Befehl nicht für Windows?