Wie scrape ich das(Python-Selenium)?
Ich habe das Problem das ich den Text oder was auch immer das ist nicht gescrapt bekomme. Ich habe wirklich schon alles versucht. Der Text lässt sich auch nicht mit der Maus kopieren, noch ist er als String im HTML Code zu finden!
Den gemeinten Part den ich gerne gescrapt gehabt hätte ist unten markiert!
Die Seite wo ihr die das findet ist diese:(nicht gleiche Aufgabe aber gleiches Prinzip)
https://mathebattle.de/edu_randomtasks/training_show/480
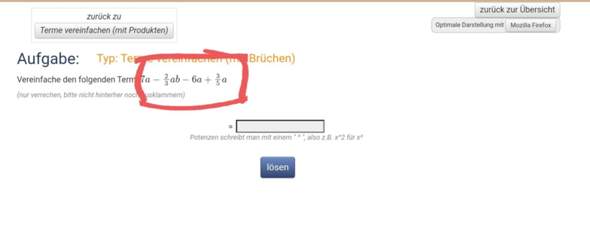
Vielen Dank für Die Antworten!
2 Antworten
Du hast Glück, dass das nicht einfach Code ist, der serverseitig in ein Bild umgewandelt wird, sondern stattdessen maschinenlesbar ist.
Es handelt sich um MathML, wie aus dem Sourcecode der Siete hervorgeht:
http://www.w3.org/1998/Math/MathML
Mit etwas Glück findest du ein Programm im Internet, dass es dir erlaubt, damit umzugehen, wie du es gerne möchtest.
Selber dafür einen Parser schreiben ist eher nicht anzuraten, das habe ich schon einmal versucht und das Ergebnis war nicht sonderlich schön. Das wäre auch mit einem Parser-Generator nicht sonderlich schön, da die Sprache Mengen und anderes Zeug enthält, dass sich pragramatisch nur bedingt umsetzen lässt.
Aber wenn du das einfach nru anderswo anzeigen möchtest, findet sich wahrscheinlich Software, die das kann, oder du kannst das evtl. direkt den Browser machen lassen, wie es dir Seite auch macht, denn offenbar (wusste ich vorher auch nicht), kannd er mit MathML umgehen.
das ich den Text oder was auch immer das ist nicht gescrapt bekomme.
Du musst doch wissen was du willst.
Text oder etwas anderes.
Was ist es denn?
Eine Bitmap ?
Wir können ja nicht wissen was du hast und was du genau willst.
Der Bezug zum Python in deiner Frage ist jedenfalls nicht klar
Dank der Antwort oben weiß ich jetzt schon mal das es MathML ist.
Das Ziel ist, diesen Term in eine Variable im Python Programm zwischen zu speichern. Allerdings weiß ich halt nicht wie ich da rangehen soll 😅
Hab gerade den HTML Code durchgeschaut. Wo findest du das MathML den immer?
Rechtcklich auf das Element und "Untersuchen". Ist bei mir unter ID "content" in einem Element mit Klasse "exercise_question".
Wohlgemerkt: Da nur manche Browser MathML unterstützen könnte ich mir vorstllen, dass das unter anderen Browsern nicht ausgeliefert wird. Unter Chrome verwendet das bei mir mjx statt MathML, entsprechend würde ich schauen, dass ich das so anfrage, dass ich MathML bekomme, wenn das nicht automatsich geschieht.
Okay, verstanden. Ich arbeite da ja mit Selenium. Wie kann ich jetzt das MathML kopieren(scrapen). Gibt es da eine extra Funktion?
Müsste man genauer untersuchen, wann das Programm entscheidet, dir da mjx statt MathML zu geben.
Was du mal ausprobieren könntest wäre, den User-Agent zu faken, sprich einen anderen als den tatsächlichen an den Server zu schicken, um diesem vorzugauckeln, dass du Firefox nutzt.
Wenn das nichts bringt, dann wird das wohl clientseitig im Javascript-Code entschieden. Da müsste man dann schauen, wie man am besten die Seite täuscht.
Ich schau mal wie weit ich komme und schreibe dir im Notfall wenn nichts mehr klappt wenn das okay ist. Vielen Dank aber schon mal
Danke! Hat mir schon sehr weitergeholfen.
Ich werde mal schauen ob ich was finde was dann das MathML in einen Text umwandelt. Mal schauen ob klappt