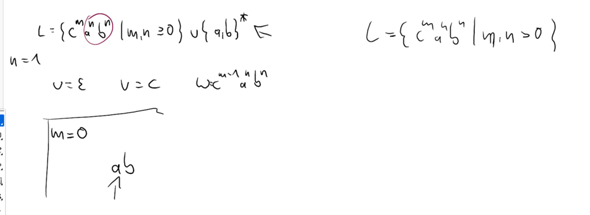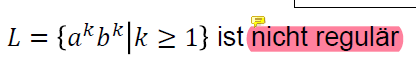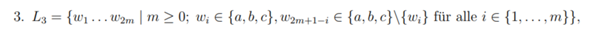Hallo,
ich arbeite gerade das Buch Compiler Engineering von Cooper durch und habe schon mehrere Fragen dazu. Vllt gibt es ja einen ITler, der mir helfen kann.
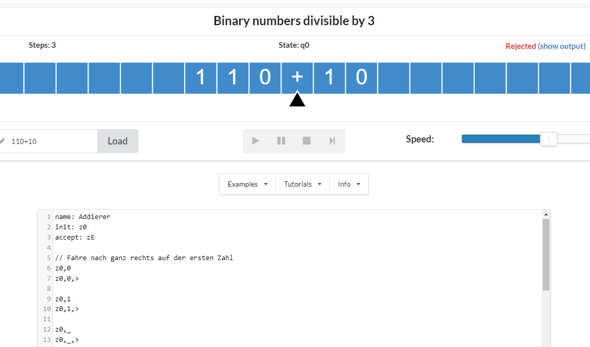
Im zweiten Kapitel habe ich reguläre Ausdrücke kennengelernt, mit welcher man eine reguläre Sprache beschreiben kann.
Der Scanner erzeugt also Wörter, die an den Parser weitergegeben werden.
Frage 1: Jetzt arbeitet der Parser mit einer regulären Grammatik, um eine Syntaxanalyse durchzuführen. Zu Beginn dachte ich, bei den Terminalen handelt es sich um Wörter aus der Sprache, aber wenn ich es jetzt richig verstehe, sind Terminale Zeichen aus dem Alphabet, über welchem die Sprache gebildet wird.
Wie erzeugt der Parser daraus eine Syntaxprüfung, wenn nicht die Reihenfolge der Wörter, sondern die, der Buchstaben analysiert wird. Sind die Grammatiken denn so komplex, dass die Wortreihenfolge kontrolliert werden kann? Bzw. wieso werden für beide Phasen dann nicht einfach eine Grammatik oder RegExes genutzt, anstatt beides zu definieren?
Frage 2: Ich dachte immer, eine Reg Gram und eine RegEx wären unterschiedliche Dinge. Hier https://de.wikipedia.org/wiki/Regul%C3%A4re_Grammatik#Regul%C3%A4re_Sprachen und im Beitrag unter Regulären Sprachen, wird aber gesagt, dass dies beide äquivalente Konzepte sind.
Was mich daran stört.
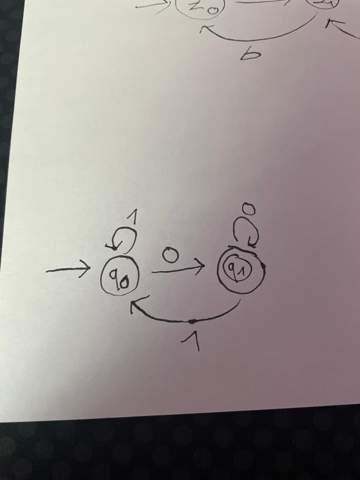
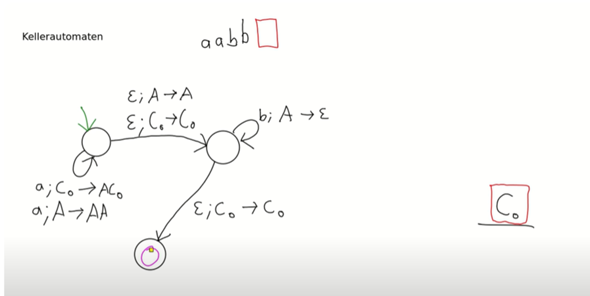
Als nicht reguläre Sprache wird häufig die Sprache L = a^n b^n genannt. Mir ist zwar bewusst, dass ich die Sprache nicht durch eine RegEx oder einen Automaten abbilden kann (von denen mir bewusst ist, dass sie äquivalent sind), aber ich könnte doch mit einer Regulären Grammatik bspw. die Ableitungsregel S -> aSb | € (epislon soll das sein :P) erzeugen und hätte damit doch eine Beschreibung für die Sprache.
Wenn RegExes und RegGrams aber äquivalent sind, dann scheine ich ja einen Fehler in der Ableitung zu machen.
Frage 3: Definition Reguläre Sprachen https://de.wikipedia.org/wiki/Regul%C3%A4re_Sprache#Definition
Hier wird beschrieben, dass eine der Bedingungen erfüllt sein muss, damit es sich um eine Reg Sprache handelt. Aber wenn eine Bedingung erfüllt ist, sind nicht gleichzeitig alle Bedingungen erfüllt?
Verwirrt mich alles ziemlich