SQL Datenbank richtig normalisieren (Für Datenbank Experten)?
Hallo,
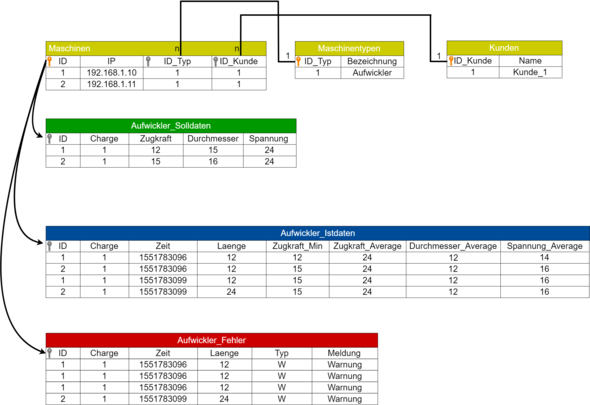
ich habe eine mySQL Datenbank mit mehreren Tabellen. Mein Problem ist hierbei, das ich kontinuierlich Prozessdaten aus Maschinen auslese und nicht weiß, wie ich die Datenbank dann normalisiere ohne Redundanzen...
z.B die Tabelle Solldaten:
Hier werden die Solldaten einer Maschine reingeschrieben, wenn sich die Charge geändert hat.
Bei der Istdaten Tabelle werden die tatsächlichen Messdaten alle 3 Sekunden in die Datenbank geschrieben
Bei der Fehler Tabelle wird nur reingeschrieben, wenn ein Fehler aufgetreten ist.
Was mir auch sorgen bereitet ist, dass 3 verschiedene Tabellen über die Primärschlüssel der Anlagen Tabelle aufgerufen werden. Macht man das so?
Meine Frage nun, ob man das nicht schöner lösen kann? Ich schreibe ja mehrfach die Charge, Zeit und die Länge in verschiedene Tabellen. Es klappt zwar so, aber es soll auch formell richtig sein.
Danke für hilfreiche Antworten
3 Antworten
Vielleicht ist es nicht schön, aber ich sehe 1:1 und 1:n-Beziehungen zwischen den Tabellen.
Eine Charge kann mehreren Maschinen zugeordnet werden und eine Maschine mehreren Chargen und das eindeutig.
Warum die Zeit hier mehrfach erfasst wird, kann ich nicht sagen. Ich nehme an, dass hier die Möglichkeit abgefangen werden sollte, dass Verzögerungen auch zu unterschiedlichen Zeiten führen können.
Den Primärschlüssel der Tabelle "Maschinen" als Primärschlüssel für die anderen Tabellen zu verwenden, halte ich nicht für gut aufgrund der Wiederholungen. Als Fremdschlüssel wäre es meiner Ansicht nach möglich, wenn zugleich ein eigener Primärschlüssel pro Tabelle gesetzt ist.
Die dritte scheint es nicht zu sein.
Ich müsste aber auf Transitivität schriftlich testen, um sicher zu gehen. Dazu fehlt mir zurzeit Zeit. Du kannst aber aus meiner Sicht immer davon ausgehen, dass wenn Du redundante Daten in die DB speichern musst, die NF3 verletzt ist.
Das ist hier recht anschaulich gemacht:
https://de.wikipedia.org/wiki/Normalisierung_(Datenbank)#Dritte_Normalform_(3NF)
Die Darstellung, die Du da geschickt hast, kann nicht die reale Konfiguration der Tabellen zeigen, bzw. zeigt sie nicht vollständig:
Jede Tabelle muss in SQL einen eindeutigen Primärschlüssel haben. Der ist hier nicht zu erkennen. Der sollte am besten eindeutig benannt sein, damit es keine Missverständnisse gibt (also nicht einfach "ID"). Dazu gibt es keine Darstellung der Beziehung zwischen den Tabellen (1:n/n:1) und der Überschneidungsart (inner join/outer join).
Leider kenne ich mich nur mit der Darstellung bei der Microsoft-Lösung aus, da ich damit arbeiten muss.^^
Zum Verknüpfen einzelner Tabellen ist es notwendig, dort einen eindeutigen Bezug herzustellen. Dass ein Primärschlüssel als Identifier dort nochmal auftaucht, ist also normal.
Was irritierend ist, dass z.B. die Charge und Zeit in mehreren Tabellen auftaucht. Eventuell fehlen in der Struktur Zwischentabellen, die eine m:n-Beziehung ermöglichen.
Die Normalisierung für Dich zu übernehmen, ist allerdings nicht möglich, weil man da eine komplette Übersicht inklusive Beziehungen benötigt und zudem ein Verständnis der möglichen Konstellationen.
Ich habe den Primärschlüssel aus der Anlagentabelle als Fremdschlüssel für die anderen 3 Tabellen genommen, da ich bei diesen eigentlich keinen Primärschlüssel bräuchte. Die 3 Tabellen sind nur mit der Anlagentabelle verknüpft.
Charge, Zeit und Länge treten mehrmals auf, weil ich zu unterschiedlichen Zeiten in die Tabellen schreibe. So wird für jede Charge nur einmal ein Eintrag in der Sollwerte Tabelle erstellt.
Bei der Istdaten Tabelle alle 3 Sekunden und bei der Fehler Tabelle nur, wenn wirklich ein Fehler auftritt. Hier können auch mehrere Fehler gleichzeitig in die Tabelle geschrieben werden.
Ich hoffe du kannst das nachvollziehen. Ich will ja z.B wissen welche Sollwerte ich bei welcher Charge habe ebenso wie ich wissen will welche Istdaten ich bei welcher Charge habe. Und bei welcher Charge der Fehler aufgetreten ist.
Du kannst einen Fremdschlüssel auch gleichzeitig als Primärschlüssel nehmen. Wenn Du, wie Du schreibst, Sätze reinschreibst, die die Zeit beinhalten, kannst gar keine Redundanz bekommen, weil die Zeit ja unterschiedlich ist. Wenn die dazugehörigen Werte sich wiederholen, ist das keine Redundanz. Wenn zwei Leute am selben Tag Geburtstag haben, hat man auch bei beiden den gleichen Wert, es ist aber nicht der selbe Wert. Denn der eine gehört zum einen, der andere zum anderen. Oder wenn es heute 20° und morgen wieder 20° hat, sind das ja nicht die selben 20°. Das muss man unterscheiden können, was gleiche Werte und was die selben Werte sind. Bei Redundanz handelt es sich um die selben Werte, die mehrfach gespeichert werden.
Ich würde eine Tabelle für die Chargen machen
Id / MaschinenId / ChargenId / Solldaten
Dann aus Istdaten und Fehlerdaten auf diese Id verlinken
Das wäre dann normalisiert, denn es gibt Maschine 1:n Chargen
Für jede Charge 1 : 1 Sollzustand, kann also in der Chargentabelle mit rein, muss aber nicht
Für jede Charge 1 : n Istzustände
Für jede Charge 1 : n Fehlerzustände
Danke schon mal! Sieht nun deutlich schlüssiger aus:
Denke so war es gemeint:
https://s16.directupload.net/images/190307/bp4mndcf.png
Ja sieht besser aus
- Die Chargen müssten eigentlich noch in eine eigene Tabelle
- Du musst dir über Keys / Indizes Gedanken machen, da Abfragen auf deiner Ist-/Fehlerdatentabelle sonst sehr lange (mehrere Minuten) dauern können wenn diese Tabellen groß werden. Da musst du schauen was für Abfragen du planst und das dann berücksichtigen
Normalisierungsstufen sind auch schön und gut, aber ich würde vor allem die Performance und Datenintegrität berücksichtigen
Müsste ich echt noch eine Tabelle "Chargen" machen?
Eigentlich sind die Solldaten (Zugkraft, Durchmesser, Spannung) ja durch ID_Charge + ID_Maschine + Chargen Nr. eindeutig identifizierbar. Somit treten ja keine Redundanzen auf.
Die Chargen Nr kann zwar bei verschiedenen Maschinen IDS gleich sein, aber das wäre ja so gesehen keine Redundanz, oder?
Aber schon mal vielen vielen Dank, so wie es jetzt ist, ist es schon mal deutlich besser.
Ja, denn eine Charge ist eine Entität die es nur einmal gibt, deshalb sollte diese eine eigene Tabelle haben (prinzipiell), dann könnte man künftig zB Chargennamen etc erweitern
Und denk unbedingt nach über die Art der Abfragen auf den Tabellen und welche Keys/ Indizes du dafür anlegen musst sonst blockiert diese Datenbank weil es so extrem ineffizient ist
Die Zeit und die Länge wird mehrfach erfasst, weil in die Tabelle "Fehler" nur reingeschrieben wird, wenn ein Fehler aufgetreten ist. Da will ich dann natürlich auch die Zeit wissen.
In der Tabelle Istdaten wird auch die Zeit erfasst, um später anfragen stellen zu können wie z.B gib mir die Prozesdaten zwischen t1 und t2.
Eine Charge gehört immer nur zu einer Maschine. Aber eine Maschine kann jedoch mehrere Chargen haben.
In der Tabelle Solldaten handelt es sich um zwei verschiedene Maschinen, welche zufällig die gleiche Chargen Nr. haben.
Welche Normalisierungsstufe ist mit diesem Design erreicht? Irgendwie eine Mischung aus 2 und 3, oder?
Danke schonmal für deine Antwort.