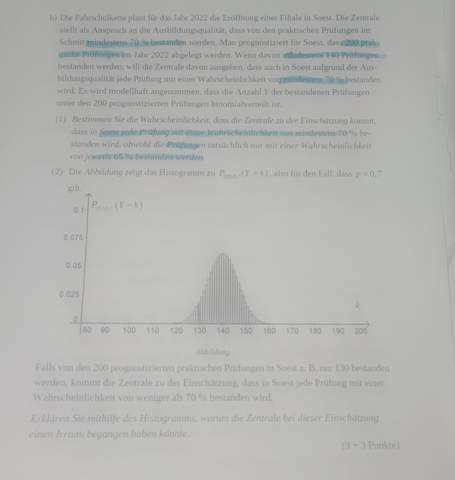
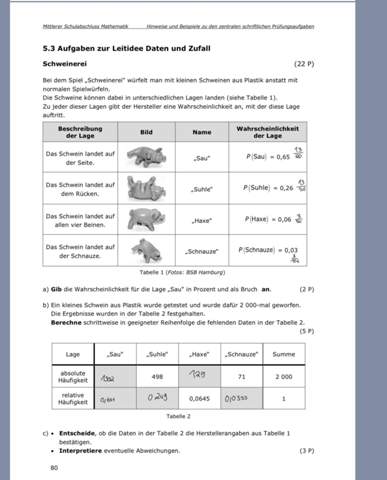
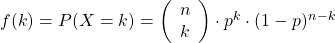Frage
Wahrscheinlichkeit bei Augen,summe eines Würfels?
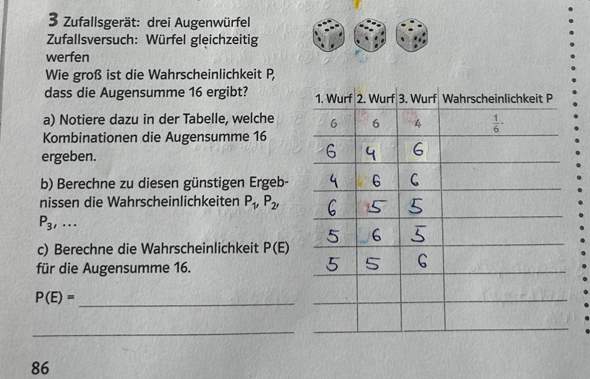
Zwei Würfel werden gleichzeitig geworfen, ich soll die Wahrscheinlichkeit berechnen, für das die Augensumme kleiner 9 ist oder größer 6
Für kleiner 9 habe ich insgesamt 26 Möglichkeit rausbekommen
Somit ist die Wahrscheinlichkeit dafür 26/36
Und für größer 6 bin ich auf 21 Möglichkeiten gekommen
somit lässt die Wahrscheinlichkeit dafür 21/36
Hier überschneiden sich doch die Wahrscheinlichkeit oder etwa nicht? ich habe also eine Schnittmenge, die nicht nur die leere Menge enthält.
Wie berechne ich das also ? Ich kann die Wahrscheinlichkeit ja nicht einfach addieren da komme ich auf >1
rechnen,
Zahlen,
Funktion,
Mathematiker,
Prozent,
Statistik,
Stochastik,
Wahrscheinlichkeit,
Wahrscheinlichkeitstheorie,
Mengenlehre,
Baumdiagramm,
Bernoulli,
Binomialverteilung,
Erwartungswert,
Kombinatorik,
Rechenweg,
Analysis