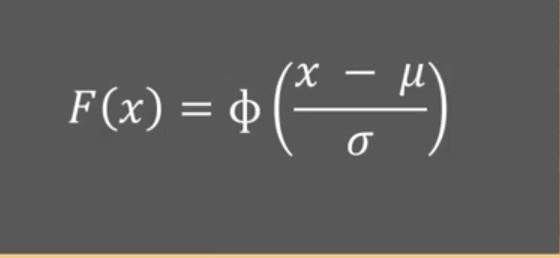Wie rechnet man die obere Normalverteilung aus?
Bitte alles genau durchlesen
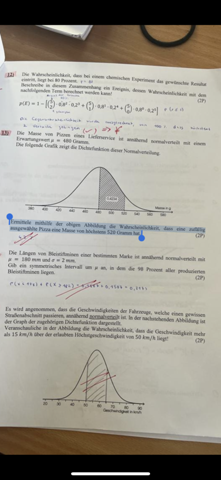
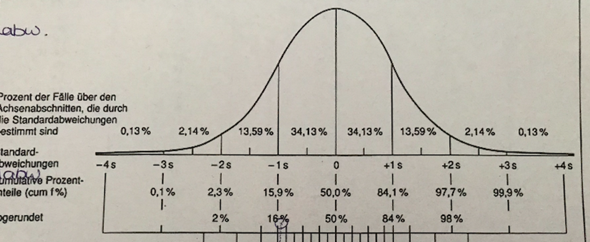
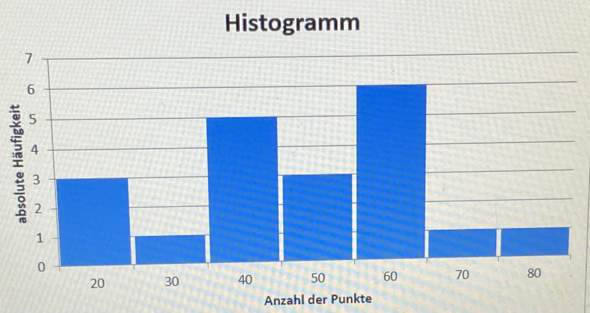
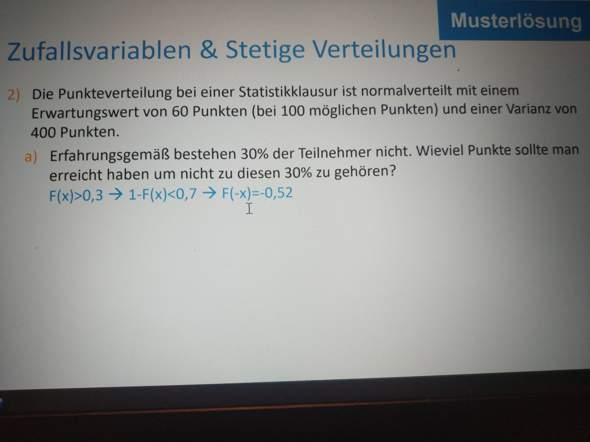
Ich soll die obere Normalverteilung einer Funktion ausrechnen.
Ich habe müh= 22, sigma = 2,1, untere Normalverteilung: 20.
Ich muss jetzt die untere Normalverteilung eingeben. Ich soll dafür auf normal cdf gehen und für die obere Normalverteilung K eintrage. Ich habe absolut gar keinen Plan, wo das ist.
Ich bin mit meinem casio fx-87DE X auf Verteilungsfunktion gegangen. Habe für müh, sigma und der unteren Normalverteilung alles eingegeben. Für die obere Normalverteilung habe ich X eingegeben.
Aber es spuckt mir nichts sinnvolles aus! Was tun?
Was ist normal cdf? Wo finde ich es? Und wo ist das K?
Lernen,
Rätsel,
Schule,
Mathematik,
rechnen,
Funktion,
Abitur,
Ableitung,
Formel,
Gleichungen,
Gymnasium,
Mathematiker,
Oberstufe,
quadratische Funktion,
Statistik,
Stochastik,
Taschenrechner,
Wahrscheinlichkeit,
Wahrscheinlichkeitstheorie,
sigma,
Binomialverteilung,
Erwartungswert,
Funktionsgleichung,
Graphen,
Normalverteilung,
Analysis