Hilfe bei Python/Greedy Algorithmus?
Ich verstehe nach mehrmaligem Herumprobieren leider nicht wieso meine Ausgabe von der Erwarteten abweicht. Hier mein bisheriger Code:

und hier die Testfälle:
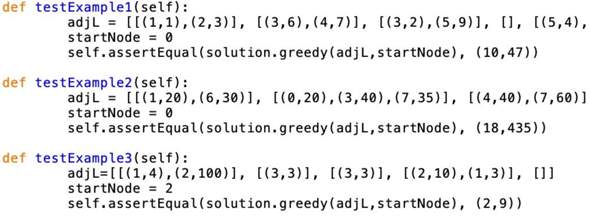
sowie meine Ausgabe:
testExample_1: (8,47)
testExample_2: (8,435)
testExample_3: (3,9)
Ich würde mich über jegliche Hilfe freuen :)
1 Antwort
Zunächst ist es kein Java, sondern Python. Dann solltest Du noch dazusagen, um welchen Algorithmus es sich handelt.
adL. und die Initialisierung lassen vermuten, daß es sich um Dijkstra o.ä. handeln könnte, zumindest etwas, das auf Adjaszenzdaten arbeitet.
Hast du Dir mal die Zwischenschritte ausgeben lassen, um den Verlauf nachzuvollziehen?
P.S.: So wie ich das sehe, scheint Dein Problem bei der Pfadlänge zu liegen, richtig? Oder ist paths die Anzahl aller möglichen Pfade?
Dijkstra ist ja greedy ;-).
Versuch mal zu erklären, unter welchem Umstand ein noch nicht besuchter NAchbar die gleichen Kosten besitzen kann, wie mein aktueller KnotenüGewicht der Übergangskante (letztes elif). Vermutlich übersehe ich etwas.
So, ich habe mir den letzten Graph mal kurz angeschaut, da sidn überhaupt nur 2 Knoten vom Startknoten erreichbar, da Du aber für die Berechnung dem Startknoten einen Pfad einträgst, erhälst Du 3 anstatt 2. D.g. am Ende der äußeren FOR-Schleife vorm sum() solltest Du beim Startknoten eien 0 eintragen.
Aber direkt am Code erkenne ich derzeitnoch nicht, warum die Ergebnisse in dne anderne beidne Fällen zu klein sind.
Anzahl aller möglichen kreisfreien Pfade, von einem gegebenen Startknoten aus
Wenn es alel Pfade sein sollen, dann sollte das doch die Sumem der kreisfreien Pfade aller Vorgänger sein, oder nicht?
Ich habe versucht den Fall zu Implementieren, dass falls zwei Pfade vom Startknoten zum Nachbarknoten über unterschiedliche Kanten führen. Beide Pfade haben die gleiche Gesamtkosten bis zu dem Zeitpunkt, an dem wir den noch nicht besuchten Nachbarknoten erreichen.
Im Code soll überprüft werden, ob der aktuelle Weg der durch 'currentNode' führt und dann über die Kante mit dem Gewicht 'weight' zum Nachbarknoten 'neighbour' führt dieselben Kosten hat wie der bisher bekannte Weg zu 'neighbour' . Wenn dies der Fall ist bedeutet dies dass man eine weitere Möglichkeit gefunden hat 'neighbour' zu erreichen, die ebenfalls kostengünstig ist.
Ich habs jetzt korrigiert und wie schon gesagt hast liefert der Code nun zum letztem Graph die korrekte Lösung.
Ja, genau so hatte ich die Aufgabenstellung ebenfalls gedeutet. Ich könnte die Aufgabenstellung ebenfalls senden, falls diese Hilfreich sein könnte.
Die Sache ist die:
Wenn Du für den Fall, daß der Nachbar mit geringeren Kosten erreichbar ist, die Pfadzahl überschreibst, dann eleminierst Du ja ein Teil der kreisfreien Pfade zu diesem Knoten.
Ein längerer Pfad (der ktreisfrei ist) ist ja noch immer ein Pfad über den der Knoten erreichbar ist.
Also müsste man um die korrekte Anzahl der kreisfreien Pfade zu gewährleisten, sicherstellen, dass man alle möglichen kreisfreien Pfade verfolgt, auch wenn man unterwegs kürzere Pfade gefunden hat. Verstehe ich das richtig?
Ich hab jetzt den Code überarbeitet und ebenfalls um 2 Hilfsfuntionen erweitert, sodass er jetzt die gewünschte Ausgabe liefert.
Vielen lieben Dank für die hilfreiche Unterstützung.
Ich könnte den überarbeiteten Code nochmal senden, falls du die Finale version sehen möchtest.
Ja, Überlegung:
Wenn ich einen Knoten besuche, dann addiere ich allen nicht besuchten Nachfolgern die eigene Pfadzahl auf - Dadurch entspricht die Summe im nicht besuchten Knoten der Summe aller Vorgänger.
Würde ich das bei besuchten Knoten machen, dann würde ich natürlich die Pfade über den Kreis in einen Vorgänger fortpflanzen, das will ich nicht.
Ich bin nur noch nicht ganz sicher, ob das so schon klappt, aber ich würde mir das eher so vorstellen:
if not visited[neighbour]:
if costs[currentNode]+weight < costs[neighbour]:
costs[neighbour]=costs[currentNode]+weight
paths[neighbour]+=paths[currentNode]
Danke erstmal für die recht schnelle Antwort.
Zuerst zum verwirrenden Titel. Ich hatte neben noch in Java etwas programmiert und aufgrund dessen die Sprache verwechselt.
Laut der Aufgabenstellung soll der klassischem Greedy-Algortihmus implementiert werden und nicht der Dijkstra.
Zwischenschritte hatte ich ebenfalls versucht kam, aber hierbei zu keiner eindeutigen Lösung warum bei meinem Code die Pfadlänge anders als bei der gegeben Lösung ist.