Python Pandas: Groupby und dabei Koordinaten behalten?
Hallo,
ich hänge gerade an einer Python Pandas Aufgabe und habe mich gefragt ob mir jemand weiterhelfen kann. Ich habe folgenden Code und bekomme folgende Ausgabe.
key_columns = ['fclass', 'long', 'lat', 'Anzahl']
df=df[key_columns]
df = df.groupby('fclass', as_index=False).count()[["fclass", "Anzahl"]].sort_values(by="Anzahl",ascending=False)
df.head()
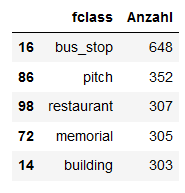
Er zählt die Anzal der Bushaltestellen und das ist schonmal gut. Leider schmeißt er aber die "long" und "Lat" Koordinaten raus. Ich habe dann folgendes versucht:
key_columns = ['fclass', 'long', 'lat', 'Anzahl']
df=df[key_columns]
df ["Anzahl"] = df.groupby('fclass', as_index=False).count()[["fclass", "Anzahl"]].sort_values(by="Anzahl",ascending=False)
df.head()
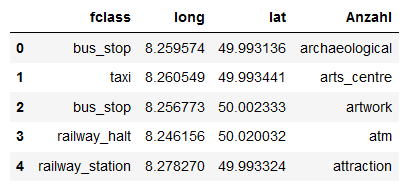
Jetzt zählt er aber nicht mehr die Anzahl der Bushaltestellen, sondern überträgt die Werte der Spalte fclass in meine Anzahl Spalte auf merkwürdige Art und Weise.
Wie bekomme ich es hin, dass er mir die Anzahl der Bushaltestellen etc. angibt und ich dennoch die Koordinaten im Dataframe habe.
Kann mir da jemand helfen?
Gruß
1 Antwort
Wenn du die Spalte "Anzahl" durch die Zahlen der ersten Tabelle ersetzen möchtest, musst du einfach die originelle Tabelle (df) und die erste Tabelle mergen:
df.drop("Anzahl", axis=1).merge(df_count_fclass, on="fclass")
Dann die Anzahl der Tabelle (df) verändert sich nicht, und die Spalte "Anzahl" zeigt die Anzahl der entsprechenden "fclass" in der originellen Tabelle.
Der Grund für die komischen Werte in der Spalte "Anzahl" ist, dass du eine Spalte (df["Anzahl"]) ein DataFrame zuordnest. Das Ergebnis der folgenden Zeile ist nämlich keine Series, sondern ein DataFrame mit zwei Spalten.
df.groupby('fclass', as_index=False).count()[["fclass", "Anzahl"]].sort_values(by="Anzahl",ascending=False)
ja ok ich vestehe. Ich muss mich glaube ich noch ein bisschen an Pandas gewöhnen :).
Danke für deine Hilfe! Mit dem mergen hat es wunderbar funktioniert.