Bäume/Informatik/Tiefensuche: Wie funktioniert die in-order-Traversierung?
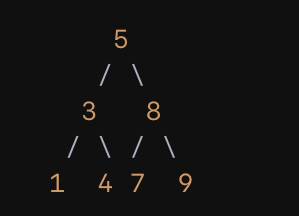
Ich verstehe die in-order bei der Traversierung nicht ganz. Zumindest nicht im Code.
Man fängt bei der 5 an und läuft rekursiv bis zur 1, also immer nach links. Danach gebe ich die 1 aus. Danach würde die 3 ausgegeben werden, sprich man klettert wieder hoch.
Ich verstehe nicht, wie das Hochklettern funktioniert. Weil nach der 1 würde man doch nach rechts springen wollen, was nicht geht, weil die 1 keine Kinder hat. Dasselbe nachdem ich die 1-3. und die 4 ausgegeben habe: Wie springe ich wieder hoch zur 5?
Also im Pseudocode verstehe ich das Prinzip schon. Immer links, Wurzel, rechts. Aber im richtigen Code nicht.
Ich habe diesen Codeabschnitt von ChatGPT:
def in_order_traversal(root):
if root is not None:
# Zuerst den linken Teilbaum durchlaufen
in_order_traversal(root.left)
# Dann den Wurzelknoten besuchen
print(root.value)
# Schließlich den rechten Teilbaum durchlaufen
in_order_traversal(root.right)
Falls ich bis zur eins ausgeben alles richtig erklärt habe würde ich zusätzlich noch gern wissen: nachdem ich die eins ausgegeben hab, würde ja folgender Befehl folgen: in_order_traversal(root.right) da sollte das Programm doch hier enden oder nicht? Weil ja die Bedingung. Root is not None nicht erfüllt wäre
3 Antworten
Da dein Beispielbaum klein ist, kannst du den Algorithmus auch gut Schritt-für-Schritt durchgehen.
Ich zeige einmal den Ablauf für den linken Teilbaum. Wir starten mit dem Wurzelknoten (n(5)):
n(5) is not None > wahr
in_order_traversal(n(3))
n(3) is not None > wahr
in_order_traversal(n(1))
n(1) is not None > wahr
in_order_traversal(None)
None is not None > unwahr
Ausgabe von 1
in_order_traversal(None)
None is not None > unwahr
Ausgabe von 3
in_order_traversal(n(4))
n(4) is not None > wahr
in_order_traversal(None)
None is not None > unwahr
Ausgabe von 4
in_order_traversal(None)
None is not None > unwahr
Ausgabe von 5
in_order_traversal(n(8))
usw. ...
Die in_order_traversal-Funktion ist rekursiv. Das heißt, sie ruft sich immer wieder selbst auf. Immer wenn der Programmfluss in einen neuen Funktionskontext wechselt, habe ich im obigen Verlauf die Einrückungsstufe weiter nach rechts gesetzt.
Da bei jedem Aufruf ein Subknoten übergeben wird, kann in der Baumstruktur nach unten geklettert werden. Die Prüfung, ob der übergebene Knoten existiert, ist die Abbruchbedingung der Rekursion. In diesem Fall ruft sich die Funktion nicht wieder selbst auf, sondern wird beendet. Somit kann der Programmfluss wieder zum Aufrufer springen (bzw. hier hochklettern).
Wofür die Einrückungen stehen, habe ich in meinem obigen Text bereits erklärt.
Im besten Fall erstellst du dir selbst eine Skizze/einen Schritt-für-Schritt-Ablaufplan. Dabei brauchst du im Grunde nur eine Regel berücksichtigen:
Wenn eine Funktion aufgerufen wird, springt der Programmfluss in deren Körper, arbeitet dessen Anweisungen ab (bis das Ende des Funktionskörpers oder eine return-Anweisung erreicht wurde) und springt anschließend zurück zum Aufrufer (bzw. hinter die Stelle des Aufrufs). Von dort geht es wie gehabt weiter.
Mithilfe des Stacks das Prinzip, verstanden. Nur geht es bei der Pre order nicht auf. Bei Pre Order tue ich erst meine Wurzel ausgeben und springe dann rekursiv in meinen linken beziehungsweise rechten Baum . die Rekursion Aufrufe werden doch im Stack abgelegt d.h. aber meine Wurzel selbst wird nicht im Steak abgelegt. Wie springe ich dann wieder zurück zur Wurzel?
Bei einer Durchquerung nach pre-order-Logik, läuft es nicht großartig anders ab, als bei in-order. Der einzige Unterschied ist der, dass bei jedem Aufruf der pre-order-Funktion der Knotenwert zuerst ausgegeben wird, bevor es weiter in die Subknoten geht.
Algorithmus (Python):
def pre_order_traversal(root):
if root is not None:
print(root.value)
pre_order_traversal(root.left)
pre_order_traversal(root.right)
Nehmen wir diesen Baum als Beispiel:
5
3 8
Arbeitsschritte, beginnend mit dem Aufruf von pre_order_traversal(n(5)):
n(5) is not None > wahr
Ausgabe von 5
Aufruf von pre_order_traversal(n(3))
n(3) is not None > wahr
Ausgabe von 3
Aufruf von pre_order_traversal(None)
None is not None > unwahr
Aufruf von pre_order_traversal(None)
None is not None > unwahr
Aufruf von pre_order_traversal(n(8))
n(8) is not None > wahr
Ausgabe von 8
Aufruf von pre_order_traversal(None)
None is not None > unwahr
Aufruf von pre_order_traversal(None)
None is not None > unwahr
Wie schon oben: Ein Einrückungsschritt nach rechts steht für einen Kontextwechsel in die aufgerufene Funktion. Wenn die Funktion vollständig abgearbeitet wurde, geht es wieder zum Aufrufer (eine Einrückung nach links). Ganz am Ende bist du wieder beim allerersten Aufrufer.
Du musst die Vorgängerknoten in einer Datenstruktur ablegen. Einem Stack üblicherweise bei der Tiefensuche, eine Queue bei der Breitensuche. Wie genau hängt davon ab wie genau du traversierst.
d.h. bei der Rekursion merkt sich das Programm Wo es schon war?
D.h einfach gesagt der Vorgängerknoten wird sich gemerkt sobald ich das Ende erreicht hab also ganz unten bin, springt man automatisch wieder zurück auf den Vorgängerknoten? Wie genau ist es dann bei der Post Order da springe ich ja sozusagen von unten links nach rechts
Bei der rekursion werden durch den Rekursionsaufruf Sprungmarken auf den Stack gelegt.
In welcher Reihenfolge dies geschieht entscheidest du durch die reihenfolge deiner Aufrufe.
Für In-Order sähe das so aus:
handle(left);
//Handle current
handle(right);
Für Post-Order entsprechend:
handle(left);
handle(right);
//Handle current
Schau dir mal an wie Rekursion funktioniert, am besten irgendwie visualisiert. Dann solltest du verstehen, wie das „hochklettern“ funktioniert.
Ich verstehe,aber auch irgendwie nicht ganz, wenn du sagst das zum aufrufer zurückgesprungen wird , wieso wird nach der 4 zur 5 gesprungen und nicht zur 3? Oder ergibt sich das mit der Einrückung die du in deinen pseudcode gemacht hast? Das ganz ist doch wohl mit Absicht verschachtelt worden. Sieht so aus, wie mehrere schleifen in einer Schleife