Wie liest man die Aminosäuren der DNA aus?
also dass man z.b.
A C C G T
T G G C A
lesen kann
2 Antworten
Moin,
zunächst musst du dir klar machen, dass die DNA ein Doppelstrang von Nukleotiden ist, der antiparallel verläuft.
Jeder Einzelstrang hat ein sogenanntes 3'- und ein 5'-Ende. Das hat etwas mit dem Zucker Desoxyribose in einem Nukleotid zu tun.
Daher wäre es schon einmal wichtig zu wissen, welcher Einzelstrang in deiner Beispielsequenz welches Ende hat:
3'-...ACC GT...5'
5'-...TGG CA...3'
oder
5'-...ACC GT...3'
3'-...TGG CA...5'
Dann kommt noch hinzu, dass einer der beiden Stränge der sogenannte Code-Strang ist. Er enthält die genetische Information für die Verschlüsselung der Aminosäuresequenz.
ABER an ihm wird NICHT die mRNA (also der Botenstoff) synthetisiert, die gebraucht wird, um die Information später auch in eine Aminosäuresequenz übersetzen zu können. Das passiert am Gegenstrang, dem sogenannten codogenen Strang.
Wenn du weißt, welcher der beiden Stränge der codogene Strang ist und die Richtung (3'-5') kennst, dann musst du verstehen, wie die Boten-RNA (mRNA) hergestellt wird (Transkription).
Dazu musst du wissen, dass dies mit Hilfe einer RNA-Polymerase geschieht. Polymerasen laufen einen DNA-Strang immer vom 3'- zum 5'-Ende kontinuierlich entlang, das heißt, dass sie Nukleotide immer vom 5'- zum 3'-Ende aneinandersetzen. Dazu musst du die Basen am codogenen Strang mit RNA-Nukleotiden paaren.
Die RNA ist - im Gegensatz zur DNA - ein Einzelstrang. Sie ist kürzer als die DNA und sie verwendet Uracil (U) anstelle von Thymin (T).
Nehmen wir mal als Beispiel wieder deine (sehr kurze) Basensequenz, nur, dass ich jetzt einiges einfach festlege:
3'-...ACC GT...-5' (codogener Strang)
5'-...TGG CA...-3' (Code-Strang)
Dann würde die mRNA am oberen Strang von links nach rechts transkribiert:
3'-...ACC GT...-5' (codogener Strang)
5'-...UGG CA...-3' (mRNA)
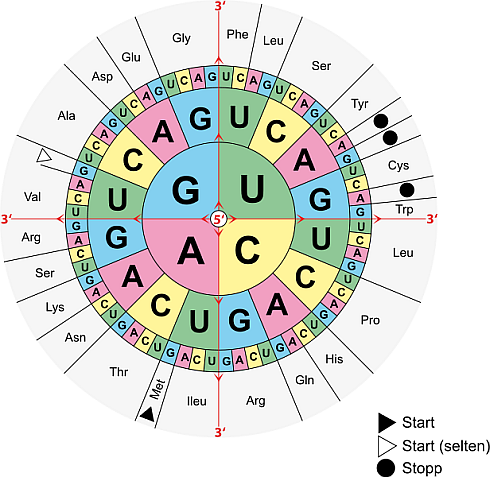
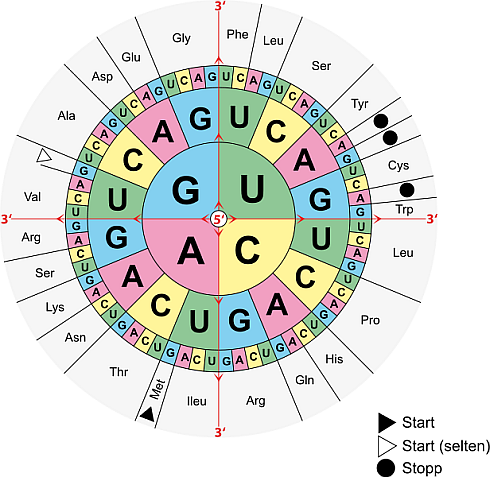
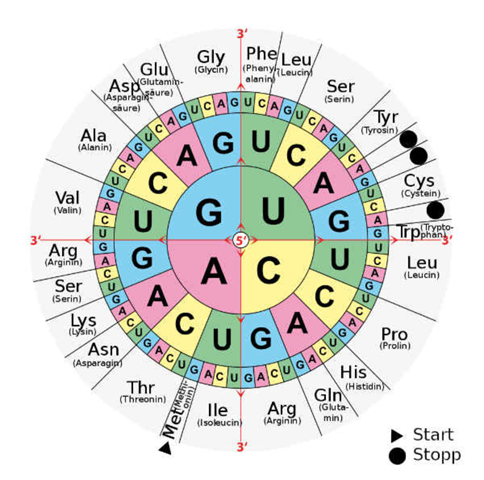
Wenn du auf diese Weise die mRNA ermittelt hast, kannst du aus einer Code-Sonne ablesen, welche Aminosäure sich aus der Basensequenz der mRNA ergeben wird.
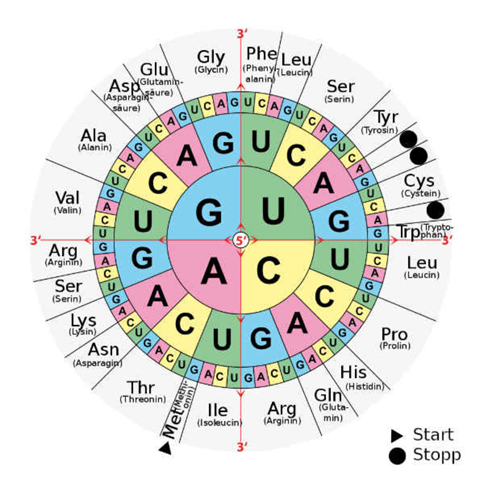
In unserem Fall wird 5'-UGG-3' in die Aminosäure Trp (Tryptophan) übersetzt. Aus dem Anfang des Tripletts 5'-CA...-3' könnte Glutamin (Gln) werden (wenn die letzte Base ein G oder A wäre) oder Histidin (His), wenn die letzte Base C oder U wäre.
Fazit:
Du musst wissen, welcher DNA-Strang welche Enden hat.
Du musst wissen, welcher DNA-Strang der Code-Strang und welcher der codogene Strang ist.
Du musst am codogenen Strang vom 3'- zum 5'-Ende die mRNA durch komplementäre Basenpaarung transkribieren. Beachte dabei, dass in der mRNA Uracil (U) statt Thymin (T) eingebaut wird.
Die fertige mRNA kannst du mit Hilfe einer Code-Sonne in die Aminosäuresequenz übersetzen (vom 5'- zum 3'-Ende hin).
Die spärlichen Angaben in deinem Beispiel lassen vier Möglichkeiten zu, je nachdem, welches Ende wo ist und welcher der codogene Strang ist.
Es könnten folgende Aminosäuren sein:
- Trp-Gln oder Trp-His (codogener Strang oben; 3' nach 5')
- Thr-Val (codogener Strang oben; 5' nach 3')
- Thr-Val (codogener Strang unten; 3' nach 5')
- Cys-Gln oder Cys-His (codogener Strang unten; 5' nach 3')
Ich hoffe, du konntest alles nachvollziehen.
LG von der Waterkant
Vielen Dank, dass du dir so viel Mühe gegeben hast. Es sei mir erlaubt für den Fragesteller anzumerken, dass man natürlich auch noch den Leserahmen kennen muss - da der genetische Code kommalos ist, muss festgelegt werden, wo das Ablesen beginnen soll und wo es enden muss. Das geschieht über die Start/Stop-Codons.
Mit der Code-Sonne:) aber Achtung: du musst die DNA-Sequenz erst in eine mRNA-Sequenz übersetzen. Dann kannst du einfach aus der code Sonne ablesen (von innen nach außen).