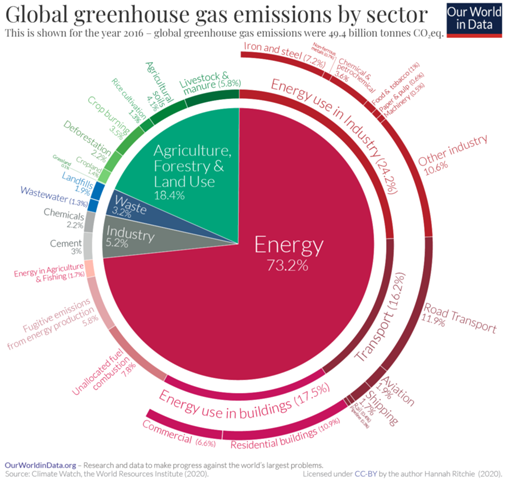
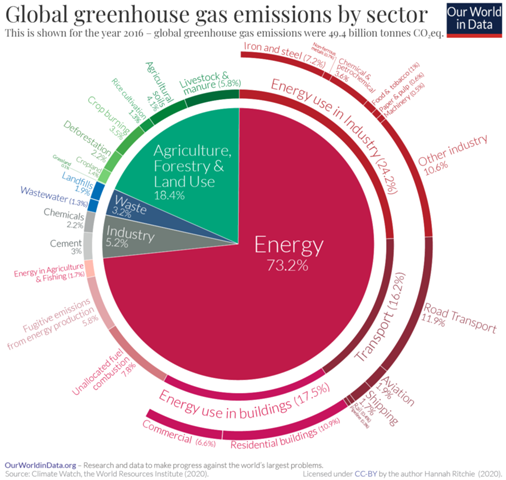
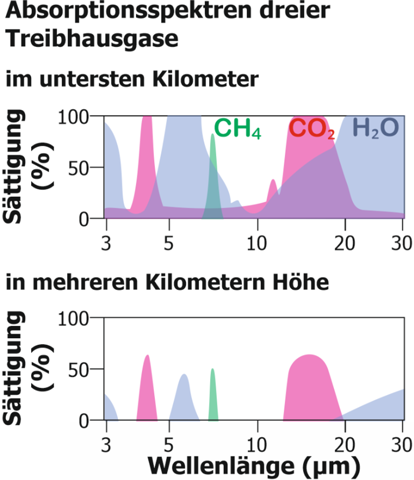
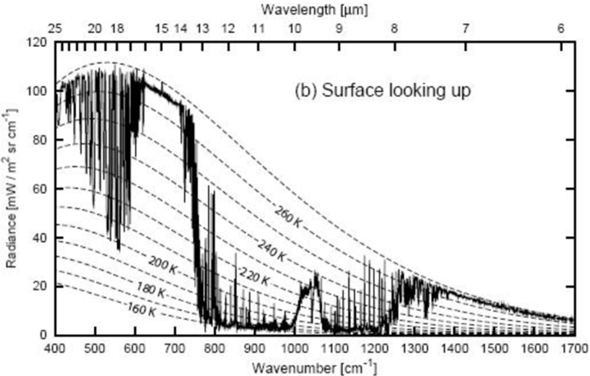
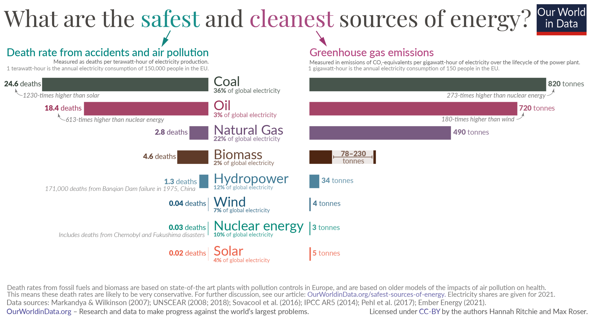
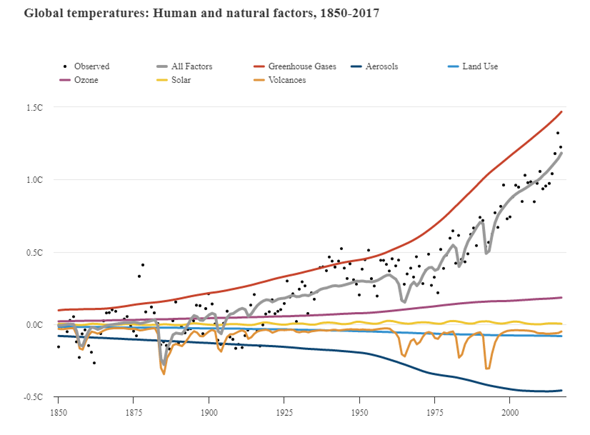
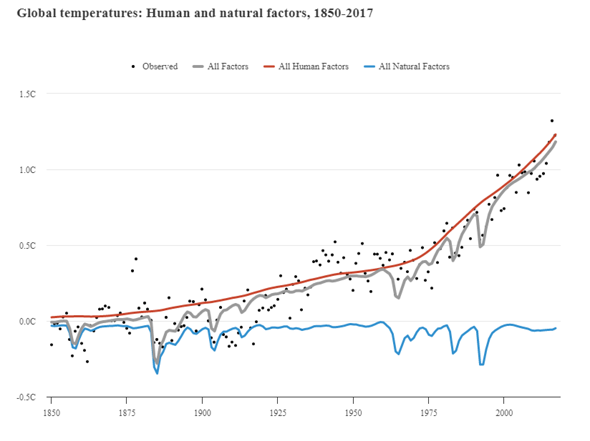
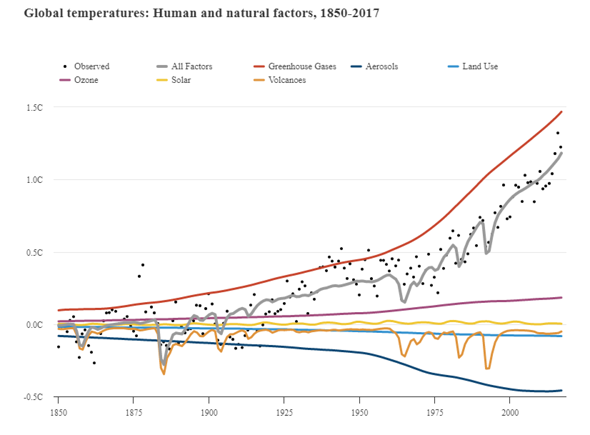
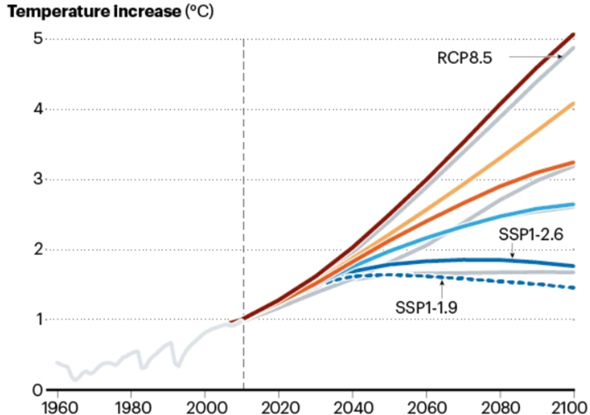
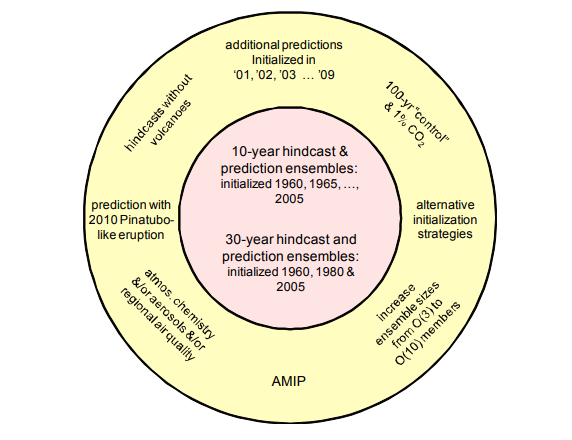
Es gibt sehr viele Klimamodelle und alle können ein bisschen anders funktionieren, weshalb ich mich hier auf die CIMP-Modelle (CIMP5) beziehe, mit welchen auch der IPCC arbeitet. Im CMIP (Coupled Model Intercomparison Project) werden unterschiedliche Modelle miteinander verknüpft (Ensemble-Methoden), um Unsicherheiten zu quantifizieren und korrigieren. Da es beim Thema Klima schwierig ist, Experimente mit empirischen Beobachtungen durchzuführen, ist die Überprüfung der Daten, die von den einzelnen Modellen eingegeben werden, kompliziert. Diese Prüfung wird mit sogenannten 'Hindcasts' durchgeführt, das heißt, Vorhersagen aus der Vergangenheit in die Zukunft, die dem aktuellen Zeitpunkt entsprechen. "Hindcasts" beziehen sich also auf das Laufen von Modellen rückwärts in der Zeit, um die Fähigkeit des Modells zur Wiedergabe bekannter Klimadaten zu testen. Durch Vergleich von Hindcasts mit realen Beobachtungen können Forscher dann die Zuverlässigkeit ihrer Modelle überprüfen und ggf. Anpassungen vornehmen, um die Genauigkeit zukünftiger Prognosen zu verbessern. Danach werden langfristige Simulationen durchgeführt, gefolgt von weiteren, detaillierteren Simulationen, die sich ausschließlich auf die Atmosphäre konzentrieren. Diese Simulationen gelten als Time-Slice-Experimente. Man unterscheidet zwischen "Near-Term" und "Long-Term". Das "Near-Term" Design sieht ausführlicher gesehen so aus:
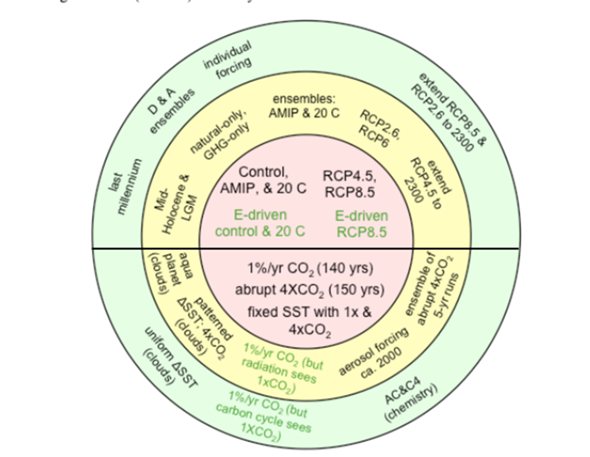
Das "Long-Term" Design wiederum so:
Die Hindcasts sind aus meiner Sicht aktuell die einzige Methode experimentell die Eignung der zugrundeliegenden Modelle zu quantifizieren, und sie anhand ihrer Abweichungen zur Messung einzuordnen. Hinzu kommt die relativ große Menge an integrierten Modellen, und die steigenden Komplexität der ermittelten Daten in den einzelnen Phasen. Phase 6 ist zum Beispiel noch einmal deutlich komplexer. Die Menge an Ergebnisdaten dieser Phasen bewegen sich inzwischen im Petabytebereich. Die Datengrundlage und der Umfang der Prognosen ist also nicht einfach aus der Luft gegriffen. Sondern eben auch aus dem Wasser und dem Boden, und aus der Vergangenheit (Proxydaten)
A Summary of the CMIP5 Experiment Design (llnl.gov)
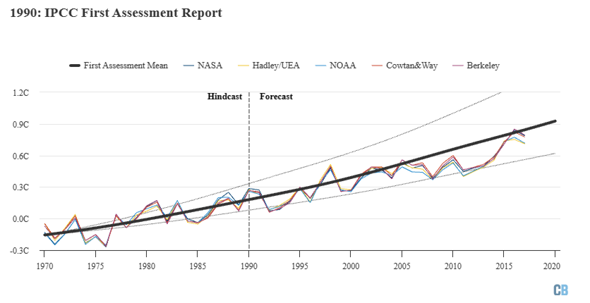
Ein kleines Beispiel des ersten Sachstandbericht des IPCC. Die gestrichelte Linie bezeichnet immer den Zeitraum, bis zu dem die Modelle sich warmlaufen konnten (hindcast) und sie sehen, wie genau das Modell dann den mittlerweile ja bekannten, aber damals eben noch nicht bekannten Temperatur-Verlauf gesehen hat. Die bunten Kurven sind die Temperatur-Rekonstruktionen, wie wir sie im zweiten Kapitel der Vorlesung diskutiert haben, gestrichelt ist der Bereich, den das Modell als 95% Wahrscheinlichkeit herausgegeben hat:
Bis zum vierten IPCC Sachstandbericht hat die Modellierung deutliche Fortschritte gemacht, wie wir sie im dritten Kapitel kennenlernten. Jetzt werden nicht nur einfache Projektionen gemacht, sondern tatsächliche Schwankungen der Vergangenheit werden berücksichtigt und ähnliche Schwankungen werden zufällig für die Zukunft angenommen:
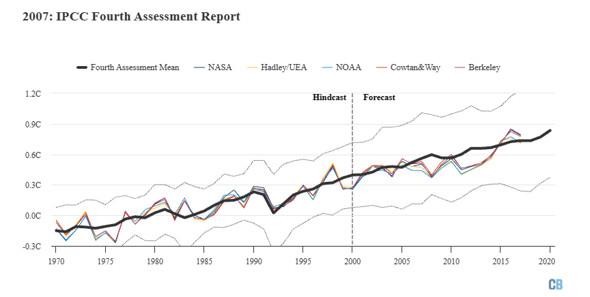
Die Modelle können also sehr gut die später tatsächlich gemessenen globalen Temperaturverläufe vorhersagen. Einen etwas anderen Ansatz verfolgt das Re-Analyse Projekt. Siehe:
RealClimate: Observations, Reanalyses and the Elusive Absolute Global Mean Temperature
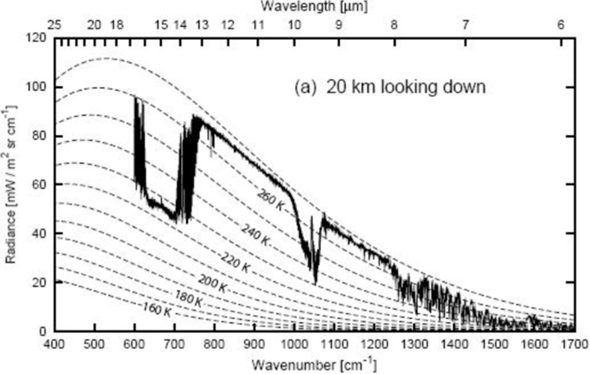
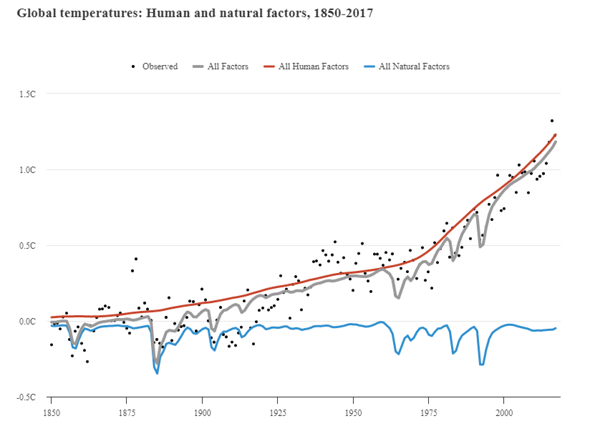
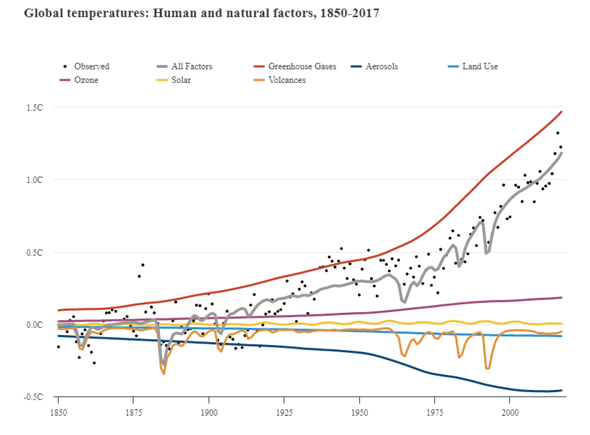
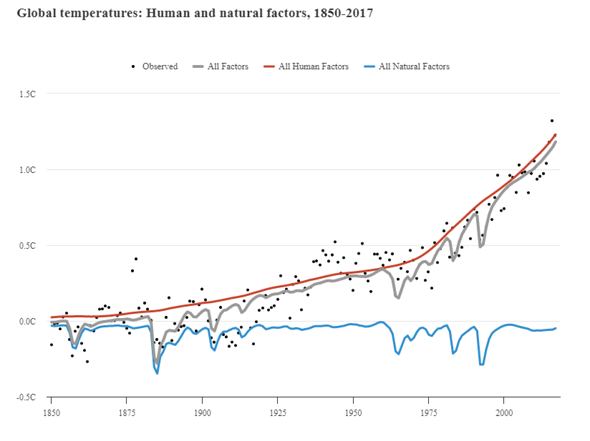
In diesem Projekt werden gemessene oder berechnete Strahlungsantriebe der Vergangenheit in die Modelle integriert und getestet, wie genau sie die tatsächlichen Werte treffen oder wie stark sie voneinander abweichen. (Siehe erste Grafik) Es zeigt sich hier ganz klar, dass die Einbeziehung von realen Einflüssen (wie auch Strahlungsantrieben) eine ausgezeichnete Reproduktion von Klimaereignissen ermöglichen. Gerade das Erdsystemmodell kann die tatsächlichen Entwicklungen beinahe filigran nachzeichnen.
Kleiner Input:
Da Modelle ohne vorherige Experimente nicht möglich wären, würde ich sie als eine Erweiterung der Experimente und Beobachtungen ansehen, nicht als eine Alternative. Der grundlegende Zweck der Experimente und Beobachtungen besteht darin, Aspekte eines Systems unter Bedingungen, die so weit wie möglich alle anderen Faktoren konstant halten (ceteris paribus), zu verstehen, um Vorhersagen über seine zukünftige Entwicklung treffen zu können. Extrapolation, die sich rein auf Experimente und Beobachtungen stützt, kommen also schnell an Grenzen, sobald sich Rahmenbedingungen ändern, insbesondere sobald sie sich außerhalb des Bisherigen befinden. Ein Modell zielt darauf ab, die Ergebnisse von Experimenten und Beobachtungen in einem Gesamtzusammenhang zu vereinen. Obwohl es gegenüber der Realität vereinfacht sein muss, bietet es den Vorteil, dass seine einzelnen Komponenten sich gegenseitig beeinflussen, wodurch es isolierten Experimenten und Beobachtungen überlegen ist. Also kurz gesagt, desto mehr Teilsysteme des Klimasystems in die Modelle integriert werden, desto näher kommen letztere der Realität; aber schon simple Atmosphärenmodelle liegen nicht weit daneben. Bereits die ersten Atmosphärenmodelle konnten übrigens Schwankungen in der Sonneneinstrahlung berücksichtigen, im Gegensatz zu immer wieder zu lesenden Behauptungen. Tatsächlich sind Modelle, in denen sich die CO2-Konzentration gar nicht ändert, sondern nur die Sonneneinstrahlung, durchaus imstande, annähernd die Erwärmung bis in die 1970er Jahre zu berechnen (hindcast). Nach dieser Zeitperiode funktioniert es jedoch im Wesentlichen nicht mehr, da die Strahlung um einen ziemlich gleichbleibenden Mittelwert oszilliert oder sogar niedrigere Maxima erreicht:
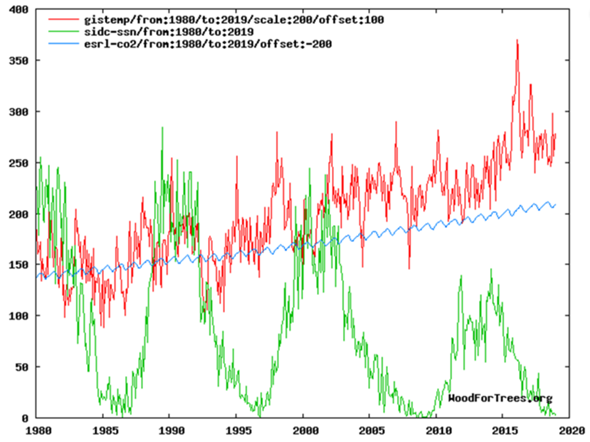
Wir wissen, dass es zwei zentrale Größen bei der ganzen Klimawandeldiskussion gibt. Die erste sind die Strahlungsantriebe. Der zweite zentrale Wert ist die Klimasensitivität des CO2. Wie frühere Modelle diese Werte projizieren konnten, ist in dieser Grafik ersichtlich. Spannend hier zu sehen ist natürlich, dass z.B. das Exxon-Modell (Sawyer) sehr nahe an der Realität war:
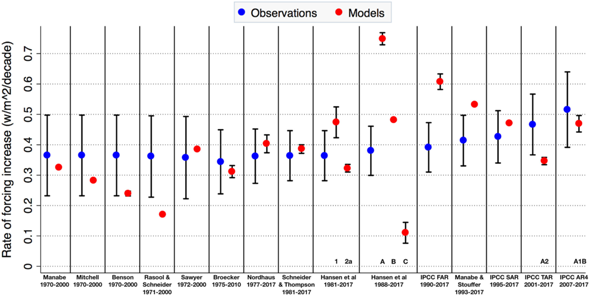
Evaluating the Performance of Past Climate Model Projections - Hausfather - 2020 - Geophysical Research Letters - Wiley Online Library
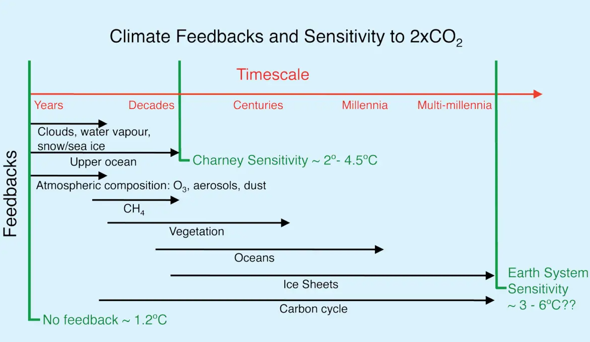
Bzgl. der Klimasensitivität von CO2 ist es komplizierter und es würde zu lange gehen dies hier ausführlich und korrekt zu behandeln. Informationen dazu findest du aber hier:
Explainer: How scientists estimate climate sensitivity (carbonbrief.org)
Bezüglich Proxydaten:
Das gute an Klimaproxies ist, dass es eine Menge unterschiedlicher davon gibt. Proxydaten haben daher auch verschieden Schwächen und Stärken. Aufgrund der grossen Anzahl an Proxydaten kann man diese miteinander vergleichen und einen grossen Anteil von Unsicherheiten entfernen. Trotzdem sind sich Wissenschaftler gewissen Ungenauigkeiten von Proxydaten bewusst und benennen diese auch. Zum Beispiel geht man bei der (lediglich auf diese Methode bezogenen) Rekonstruktion mittels Sauerstoffisotopen - also dem Verhältnis der Isotope ¹⁶O und ¹⁸O, gemeinhin ausgedrückt als δ¹⁸O - von einem Fehler je nach Studie von zwischen 0,5 °C und 1,5 °C aus. Diese Fehler/Unsicherheiten sind also bekannt und werden auch so behandelt. Ein Klimamodell wird dadurch nicht verfälscht.