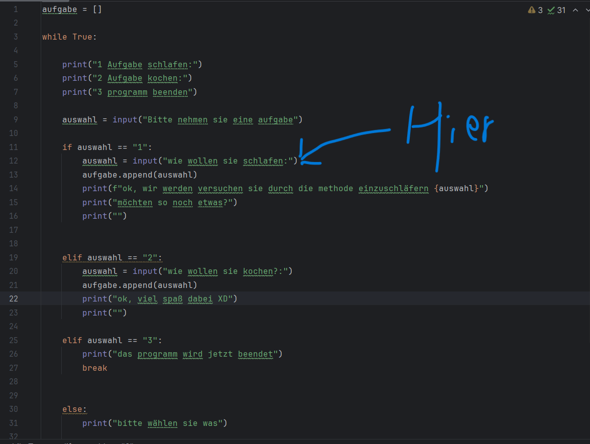
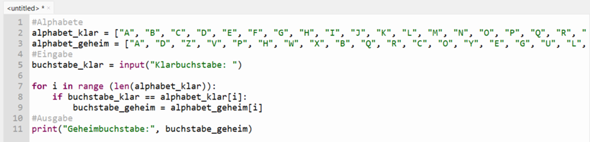
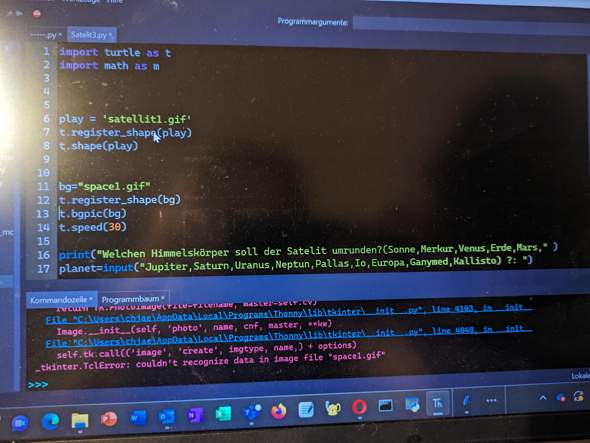
Moin, hab durch meine Langeweile nach neuen Projekten gesucht und bin darauf gestoßen ein Programm zu schreiben welches mir die Destination IP durch das scannen eines ports gibt. Hab es erst als mit einer TCP Verbindung versucht damit hat alles geklappt dann wollte ich es mit einer UDP Verbindung testen und natürlich musste ich dafür einen neuen Code schreiben allerdings klappt das ganze nicht so wie ich es mir vorstellt und komme nicht drauf wie ich es anders machen könnte. Ich hab das ganze an einem CS2 server versucht und hab mich mit einem Public server verbunden, in Wireshark wird mir das ganz normal angezeigt in meinem Programm wird mir leider trotzdem nichts angezeigt :/Keine Ahnung ob ich einen Denkfehler habe oder komplett falsch an die sache rangegangen bin. Gerne Vorschläge + Danke im Voraus :) Hier mein Code:
import socket
def check_port(port):
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
try:
host = socket.gethostbyname(socket.gethostname())
sock.bind((host, port))
print(f"Port {port} ist offen und bereit.")
print(f"Checking {host}:{port}")
while True:
data, addr = sock.recvfrom(1024)
print(f"Empfangene Daten von {addr[0]}:{addr[1]}: {data}")
except OSError as e:
print(f"OS Error{port}: {e}")
finally:
sock.close()
if __name__ == "__main__":
port = 27015
check_port(port)